.png)
%20%E6%8B%B7%E8%B4%9D-jxtl.jpg)

【摘要】剖析3DThinker框架,揭示其如何通过在推理链中嵌入三维潜在表示,赋予视觉语言模型(VLM)内生性的空间想象与推理能力,突破传统AI的“二维瓶颈”。

引言
在人工智能迈向通用智能的征途中,一个根本性的挑战始终横亘在前,即如何让机器真正理解并与之交互我们所处的物理世界。人类认知系统的一项卓越能力,在于能够从有限的二维视觉输入(例如一张照片)中,迅速构建起一个完整、动态的三维心理模型。我们不仅能识别图像中的物体,更能推断它们的空间关系、遮挡状态、以及在不同视角下的形态。这种能力是我们在三维世界中导航、规划和操作的基础。
然而,当前主流的视觉语言模型(VLM)在这一维度上表现出明显的局限性。它们在图像识别与文本描述任务上取得了巨大成功,堪称“看图说话”的专家,但其对世界的理解很大程度上仍停留在二维平面。当面对需要三维一致性推理的任务,例如判断沙发背后是否能藏人、从客厅到厨房的最佳路径、或理解一个物体旋转后的样子时,模型的表现便会急剧下降。这种“空间盲区”极大地限制了AI在自动驾驶、具身智能机器人、增强现实(AR)等关键领域的应用深度。这些领域需要的不是一个二维图像的描述者,而是一个三维世界的理解者与行动者。
为了打破这一瓶颈,业界探索了多种路径,其中以外挂三维重建或深度估计等外部工具的方案较为常见。这类方法虽在特定场景下有效,但往往伴随着高昂的硬件成本、复杂的数据依赖以及脆弱的系统集成问题,难以形成一个通用、鲁棒的解决方案。清华大学深圳国际研究生院联合美团、新加坡国立大学提出的3DThinker框架,则另辟蹊径。它没有选择外部“义肢”,而是致力于在模型内部构建一种内生性的三维想象能力,让AI在语言推理的过程中,同步进行“脑内建模”。这项工作为解决AI的空间感知难题提供了一个全新的、极具启发性的范式。
一、 空间智能的困境与范式之争
%20拷贝-hjkl.jpg)
人工智能对三维空间的理解能力,直接决定了其在物理世界中的应用上限。在深入3DThinker的技术细节之前,有必要厘清当前VLM在空间推理上面临的具体挑战,以及主流技术路线的范式分野。
1.1 VLM的“空间盲区”:从识别到推理的鸿沟
现代VLM通过海量图文对的预训练,学习到了强大的视觉概念与语言的对齐能力。但这种学习本质上更侧重于语义层面的关联,而非几何层面的构建。其“空间盲区”主要体现在以下几个方面。
三维一致性缺失:模型可以识别出多张图片中都存在“桌子”和“椅子”,但难以判断这些图片中的桌椅是否为同一组物体,以及它们在统一三维空间中的相对位置是否一致。
遮挡关系推理不稳:对于被部分遮挡的物体,模型或许能猜出其身份,但无法准确推断其被遮挡部分的完整形态和空间占用,这对于路径规划和安全判断至关重要。
跨视角理解困难:当一个物体以不同角度呈现在多张图片中时,模型很难建立起它们是同一物体的认知,并理解其旋转变换的几何逻辑。这在机器人抓取、物体追踪等任务中是基础能力。
可通行性与可达性判断失效:模型无法仅从几张室内照片中,可靠地规划出一条从A点到B点的无碰撞路径,因为它缺乏对空间布局、物体尺寸和通道宽度的综合三维感知。
这些问题的根源在于,模型的推理过程缺少一个用于承载和操作三维几何信息的工作记忆区。它只能在二维特征和文本符号的浅层空间里打转,无法跃升到三维几何空间进行思考。
1.2 两种技术范式:外挂工具 vs. 内生能力
为弥补VLM的空间短板,业界形成了两种截然不同的技术范式。
1.2.1 “外挂工具”范式 (Tool-Augmented Approach)
这种范式将VLM视为一个高级控制器或语义理解中心,为其配备一系列专门处理三维信息的外部工具。其工作流程通常如下:
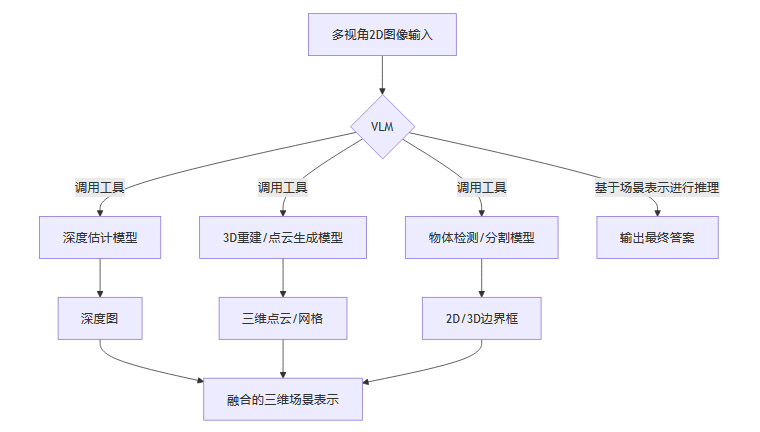
优势在于模块化,可以利用各个领域的最佳模型(SOTA),快速搭建一个具备初步三维感知能力的系统。
劣势也同样明显:
系统脆弱性:整个流程是一个串联的工具链,任何一个环节的错误都可能被放大,导致最终结果的失败。
延迟与效率问题:多次模型调用和数据转换带来了显著的计算开销和时间延迟,不适用于实时性要求高的场景。
信息损失:在模块间传递信息时,原始数据中的丰富细节可能丢失,例如从图像到点云的转换会损失纹理和光照信息。
泛化能力受限:工具模型通常在特定数据集上训练,对新场景的适应性有限,导致整个系统的泛化能力受限于最弱的那个工具。
1.2.2 “内生能力”范式 (End-to-End Approach)
该范式追求在模型内部直接构建处理和推理三维空间的能力,将空间理解内化为模型自身的一部分。3DThinker正是这一范式的典型代表。其核心思想是,不依赖外部拼装,而是让模型在统一的框架内,端到端地完成从多模态感知到空间推理的全过程。
优势在于:
系统统一性:所有计算都在一个模型内部完成,避免了复杂的模块集成和数据接口问题。
高效率:端到端推理减少了中间环节,具有更低的延迟和更高的计算效率。
信息保真度:模型可以直接在内部的多模态特征上进行联合推理,最大限度地保留了原始信息。
更强的泛化潜力:通过端到端的联合训练,模型有望学习到更深层次、更本质的空间与语义的关联,从而获得更好的泛化能力。
3DThinker的出现,标志着“内生能力”范式取得了重要进展。它证明了让VLM在推理过程中自发地进行“三维想象”是完全可行的。
二、 3DThinker框架解析:构建AI的“三维心像”
3DThinker的核心贡献在于设计了一套机制,让模型能够在标准的自回归生成过程中,无缝地嵌入一个用于三维空间推理的“心理工作台”。这个工作台并非物理存在,而是通过特殊的**三维潜在表示(3D Latent Representation)**来实现的。
2.1 核心思想:在推理链中生成“三维草稿”
人类在解决复杂空间问题时,语言思考和空间想象是交织进行的。例如,当被问及“书架能放进沙发和茶几之间吗?”,我们的大脑活动可能是:“首先,我需要想象一下沙发和茶几的位置关系(空间想象),它们之间大概有1米宽。然后,我需要回忆一下书架的宽度(语义/记忆提取),大概是80厘米。因为80厘米小于1米,所以结论是可以放进去(逻辑推理)。”
3DThinker正是模拟了这一过程。它让VLM在生成文本推理链(Chain-of-Thought)时,可以在关键节点主动插入一段特殊的标记,这些标记所包裹的内容,就是模型对当前场景生成的“三维心理草稿”。
一个简化的推理过程可能如下:
输入问题:从这几张图看,椅子是否挡住了通往书架的路?
模型推理链:
首先,我需要理解房间的整体布局。
<|latent_start|>[代表椅子、书架和地板等关键物体的三维几何特征的向量序列]<|latent_end|>根据我构建的三维场景,椅子位于房间中央,而书架靠墙。从门口到书架的直线路径确实被椅子占据了。
因此,结论是:是的,椅子挡住了通往书架的路径。
这里的<|latent_...|>部分,就是3DThinker的核心创新。它不再是简单的文本符号,而是承载了丰富三维几何信息的潜在向量,是模型进行后续空间判断的直接依据。
2.2 关键设计:三维潜在标记与投影器对齐
要实现上述思想,需要解决两个关键技术问题:
如何在模型的词汇表和架构中表示这些“三维草稿”?
如何确保这些“草稿”画的是对的,即与真实的三维几何保持一致?
3DThinker通过**三维潜在标记(3D Latent Tokens)和投影器(Projector)**给出了答案。
2.2.1 三维潜在标记
研究团队在VLM的词汇表中加入了几个特殊的Token,例如<|latent_start|>、<|latent_end|>以及一系列用于填充的<|latent_pad|>。当模型在生成过程中输出<|latent_start|>时,它就切换到了“三维想象”模式。随后生成的一系列<|latent_pad|>的隐状态向量(hidden states)并不会被解码为文本,而是被收集起来,共同构成一个三维潜在特征张量(3D Latent Feature Tensor)。这个张量就是模型对场景的内部三维表示。
研究发现,将这段三维想象片段放置在推理链的开端,效果通常最好。这符合人类“先观察形成整体印象,再进行具体分析”的认知习惯,也避免了在生成流畅自然语言的中间过程被打断。
2.2.2 投影器对齐机制
仅仅生成一个潜在特征张量是不够的,必须有一个“导师”来评判这个“想象”是否准确。3DThinker巧妙地利用了一个预训练好的、强大的三维基础模型(如VGGT)作为“想象导师”。
其对齐机制如下:
目标特征提取:将输入的多视角图像送入三维基础模型,提取出一个“标准答案”式的三维场景特征,我们称之为目标三维特征(Target 3D Feature)。这个特征代表了对场景几何结构的精确编码。
投影器映射:将VLM生成的三维潜在特征张量送入一个轻量级的投影器(通常由几层MLP构成)。投影器的作用是将VLM的“想象”特征,映射到与三维基础模型相同的特征空间中。
对齐损失计算:计算经过投影器映射后的特征与目标三维特征之间的差异(例如,使用Frobenius范数)。这个差异作为三维对齐损失(3D Alignment Loss),被用于模型的梯度下降优化。
这个过程就像是让一个学生(VLM)画一张建筑的三维草图(三维潜在特征),然后一个经验丰富的建筑师(三维基础模型)也画一张标准的(目标三维特征)。投影器则相当于一个翻译器,把学生的草图语言转换成建筑师能懂的语言。最后通过比较两张图的差异,来指导学生如何改进自己的空间想象能力。
这种设计最大的优势在于避免了对大规模、精细化的人工三维标注(如点云、mesh)的直接依赖,极大地降低了训练成本。
2.3 训练策略:从模仿到强化的双阶段进化
一个强大的空间推理能力不是一蹴而就的。3DThinker设计了一个循序渐进的双阶段训练流程,模拟了从学徒到专家的成长路径。
2.3.1 第一阶段:监督微调(Supervised Fine-Tuning, SFT)
此阶段的目标是让模型先“学会”如何在推理链中正确地使用三维想象符号,即模仿学习。
数据生成:研究团队利用GPT-4o这样的强大多模态模型,生成大量高质量的、包含三维想象片段的推理链样本。这些样本为3DThinker提供了一批“教学案例”。
训练目标:此阶段的损失函数主要由两部分构成:
语言建模损失(Language Modeling Loss):确保模型生成的文本部分流畅、连贯、符合逻辑。
三维对齐损失(3D Alignment Loss):如前所述,确保模型生成的“三维草稿”在几何上是准确的。
通过SFT阶段,模型初步掌握了在思考过程中“画草稿”的基本功,能够稳定地生成格式正确且内容初步靠谱的三维潜在表示。
2.3.2 第二阶段:强化学习(Reinforcement Learning, RL)
模仿学习只能让模型达到“老师”的水平,要实现超越,则需要通过实践和结果反馈进行自我优化。RL阶段就是**“实战演练”**。
策略与奖励设计:模型(作为Agent)生成的完整推理链(包括文本和三维潜在表示)被视为一个行动序列(Action)。系统会根据这个序列的最终效果,给予一个综合的奖励信号(Reward)。
多维度奖励函数:这个奖励函数设计得非常精妙,它同时优化三个目标:
答案准确性奖励(Answer Correctness Reward):这是最终目标。如果模型给出的最终答案是正确的,就给予高奖励。
格式规范性奖励(Format Regularity Reward):确保模型输出的推理链符合预设的结构,没有出现语法错误或不规范的标记使用。
三维一致性奖励(3D Consistency Reward):继续使用三维对齐损失作为奖励的一部分,持续激励模型提升其空间想象的质量。
通过最大化这个综合奖励,模型学会在多种可能性中,选择那个既能导出正确答案,又在空间上最为合理的推理路径。这种方式让三维想象不再是形式化的输出,而是真正服务于解决问题的核心环节。
下面的流程图清晰地展示了这一双阶段训练过程:
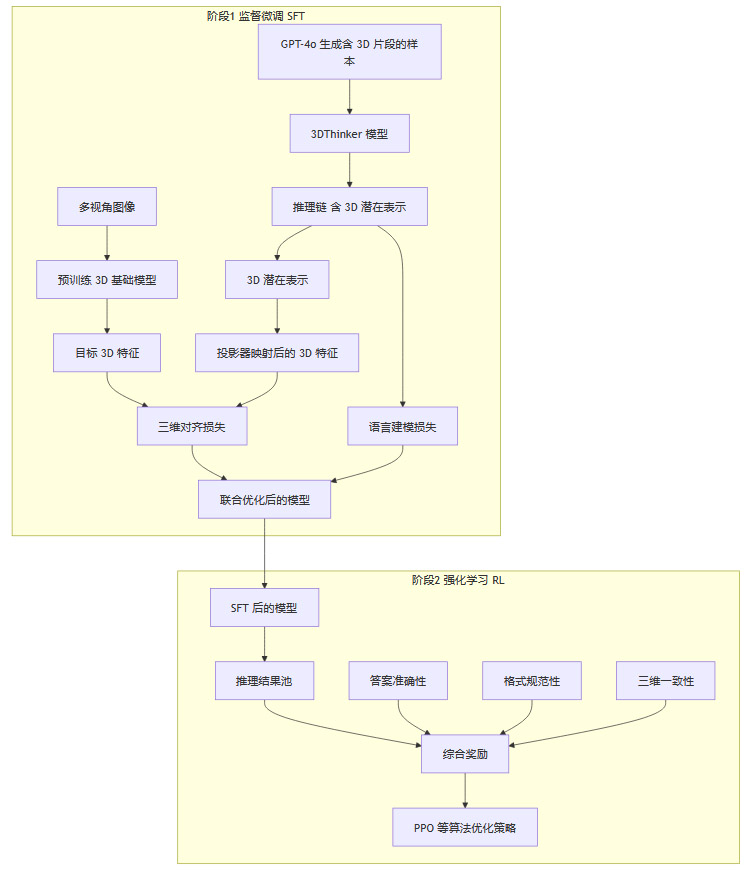
通过这一套精巧的设计,3DThinker成功地将抽象的空间想象能力,量化为了可学习、可优化的具体技术实现。
三、 实验验证:从数据看“空间想象力”的价值
%20拷贝-iqlw.jpg)
一个框架的优越性最终需要通过严谨的实验数据来证明。研究团队在一系列专门为测试空间理解能力设计的基准数据集上,对3DThinker进行了全面的评估。实验结果不仅验证了框架的有效性,也揭示了其在不同维度上的优势。
3.1 基准测试中的卓越表现
实验主要在MindCube-Tiny等数据集上展开,该数据集包含了多种需要从有限视角推断完整三维空间布局的任务,非常适合检验模型的空间推理能力。
3.1.1 核心任务性能对比
下表汇总了3DThinker在三个核心任务上与基线模型(以Qwen2.5-VL-72B为例)的性能对比。数据清晰地展示了“三维想象力”带来的巨大提升。
从数据中可以解读出几个关键信息:
全面且显著的提升:3DThinker在所有测试的空间任务上都取得了大幅度的性能增益,尤其是在对空间关系理解要求最高的“相对位置推理”任务上,准确率几乎翻倍。这直接证明了内生性的三维推理远比依赖二维线索更为可靠。
解决了传统模型的痛点:基线模型在这些任务上的表现普遍不佳(准确率多在50%以下),说明这确实是传统VLM的“阿喀琉斯之踵”。3DThinker的成功,意味着它精准地补上了这块短板。
3.1.2 模型规模的普适性
为了验证该方法的通用性,研究团队在不同参数规模的基础模型上都集成了3DThinker框架。实验结果表明,无论是3B参数的小型模型,还是72B参数的大型模型,在应用3DThinker后都获得了相似幅度的性能提升。
这一发现意义重大,它说明3DThinker所赋予的“三维思维”能力,并非某个特定大模型的偶然产物,而是一种通用的、可插拔的增强模块。这为该技术在不同算力资源和应用场景下的部署提供了广阔空间。
3.1.3 跨数据集的泛化能力
模型是否只在“题库”中表现优异,而在面对新问题时失效?为了检验泛化能力,研究团队在未经专门训练的Ego3D-Bench数据集上对3DThinker进行了测试。结果显示,模型依然取得了一致的性能提升。
这证明了3DThinker学习到的不仅仅是针对特定数据集的“应试技巧”,而是一种可迁移的、底层的空间推理能力。模型能够将其在训练数据中学到的空间想象范式,应用到全新的场景和数据分布中。
3.2 可解释性亮点:让“想象”变得可见
3DThinker最令人兴奋的特性之一,是其内在的推理过程不再是一个无法窥探的“黑箱”。通过前文提到的投影器,模型生成的三维潜在表示可以被直接解码并可视化为三维点云。
3.2.1 空间推理过程的可审计性
这种可视化能力为我们提供了一个前所未有的窗口,去观察AI的“思考”过程。
验证空间假设:当模型给出一个关于空间关系的答案时,我们可以通过检查其生成的点云,来判断它所依据的空间结构假设是否合理。例如,如果模型判断“椅子挡住了路”,其生成的点云中,椅子的位置和形态应该清晰地呈现在路径上。
诊断错误来源:当模型出错时,可视化结果可以帮助我们快速定位问题。错误可能源于对物体尺寸的误判、对相对位置的理解偏差,或是场景整体结构的构建失败。这些在点云中都能直观地体现出来。
3.2.2 思维焦点的可视化
更有趣的发现是,可视化点云的清晰度分布,往往与当前问题的核心要素高度相关。
案例分析:当被问及“椅子是否挡住了通往书架的路径”时,生成的点云中,与椅子、书架以及它们之间地面路径相关的区域会特别清晰和密集,而与问题无关的墙角、天花板等区域则可能较为稀疏或模糊。
注意力机制的体现:这表明,模型的三维想象过程并非对整个场景进行无差别的重建,而是一种带有注意力的、任务驱动的构建过程。它会智能地将更多的“计算资源”投入到与解决当前问题最相关的空间区域。
这种可解释性对于安全关键领域(如自动驾驶、医疗诊断)的应用至关重要。它将AI的决策过程从一个不可信的“黑盒”,转变为一个可以被审查、被理解、被信任的“白盒”。
四、 应用前景与行业影响
3DThinker所代表的内生性空间智能技术,一旦成熟并广泛应用,将对多个行业产生颠覆性的影响。它将推动AI从一个数字世界的“信息处理器”,转变为一个能够与物理世界深度交互的“智能实体”。
4.1 核心应用领域的能力跃迁
自动驾驶:
场景:车辆仅依靠几个车载摄像头,行驶在复杂的城市街道,前方有公交车遮挡了部分路口。
3DThinker赋能:系统不再仅仅识别出“公交车”,而是能在“脑中”构建一个包含被遮挡区域的三维场景模型,推断出公交车背后可能存在的行人或车辆,并提前做出减速或变道规划。这将极大提升自动驾驶在非结构化道路和遮挡场景下的安全性和可靠性,并有望降低对昂贵的激光雷达等传感器的依赖。
具身智能与家用机器人:
场景:用户通过语音指令,让家庭服务机器人“去卧室把桌上的蓝色杯子拿过来”。
3DThinker赋能:机器人仅凭在客厅观察到的几个视角,就能构建出整个房屋的拓扑地图和三维布局。它能理解“卧室”在哪个方向,规划出绕开沙发、茶几的最优路径,进入卧室后,即使杯子被书本部分遮挡,也能准确识别并规划抓取动作。这使得机器人的自主导航和操作能力实现了质的飞跃。
增强现实(AR)与虚拟现实(VR):
场景:用户戴上AR眼镜,希望在自己的客厅里预览一款新沙发的摆放效果。
3DThinker赋能:AR系统能通过眼镜的摄像头快速、实时地扫描并理解客厅的三维空间,包括地面、墙壁和现有家具的精确位置。虚拟沙发可以被无缝、且符合物理逻辑地放置在场景中,实现逼真的虚实遮挡和光影交互,极大地提升了沉浸式体验。
4.2 拓展应用领域的想象空间
除了上述核心领域,这项技术还将在更广泛的行业中催生新的应用范式。
4.3 对AI技术发展的深远影响
3DThinker的探索,为多模态AI的未来发展指明了一个重要方向:深度融合而非浅层拼接。它启示我们,真正的多模态智能,不应仅仅是文本、图像、声音等模态信息的简单对齐,而应是在模型内部形成一个统一的、跨模态的表示空间,在这个空间里,语义和几何、逻辑和感知能够协同推理。
这预示着,未来的大模型架构可能会朝着更加统一和融合的方向演进,探索统一的多模态词汇表(Tokenizer)和跨模态的注意力机制,让三维空间信息能像文本一样,在模型中自由、流畅地生成和传递。
五、 挑战与未来展望
%20拷贝-labr.jpg)
尽管3DThinker取得了突破性进展,但通往通用空间智能的道路依然漫长。当前框架仍存在一些局限,同时也为未来的研究指明了方向。
5.1 当前的局限性
三维表示的交互性:目前的三维潜在表示更像是在推理过程中的一个“静态快照”或“阶段性草稿”,它为后续的文本推理提供了依据,但尚未完全实现与后续推理步骤的自回归式动态交互。理想状态下,模型应该能够在其三维想象中进行多轮次的“推演”和“修正”。
计算开销与效率:生成和对齐三维表示需要额外的计算资源。如何在保证空间建模精度的同时,进一步优化算法,降低算力消耗,是工程落地前必须解决的问题。
动态与复杂场景的处理:当前的研究主要集中在静态场景。如何将这种能力扩展到包含运动物体、复杂交互的动态三维场景,是下一个巨大的挑战。
5.2 未来的研究方向
统一多模态符号体系:探索一种能将文本、图像、三维几何、甚至声音和动作等信息,都编码到同一个符号空间下的新模型架构。这将是实现真正意义上跨模态深度融合的关键。
迭代式三维推理:研究支持多轮次、可修正的三维推理机制。模型不仅能生成一个初始的三维假设,还能根据新的信息或推理的中间结果,对其进行迭代式的优化和完善。
数据效率与小样本学习:虽然3DThinker减少了对显式三维标注的依赖,但仍需要高质量的多视角数据。未来需要探索更高效的数据利用方式,甚至在小样本或零样本的条件下激发模型的空间想象能力。
安全性与鲁棒性评估:随着技术走向应用,必须建立一套完善的评估体系,系统地测试模型在面对对抗性攻击、传感器噪声、以及罕见场景(Corner Cases)时的鲁棒性和安全性。
结论
3DThinker框架的提出,是人工智能在空间认知能力上的一次范式级跃迁。它通过在模型的推理链中巧妙地嵌入“三维想象”机制,成功地让AI从一个只能“看图说话”的二维观察者,进化为了一个能够在“脑内建模”的三维思考者。这项工作不仅在多个空间推理任务上取得了SOTA级别的性能,更以其创新的“内生能力”范式、无需昂贵标注的训练策略以及可解释的可视化特性,为整个领域带来了深刻的启示。
它清晰地告诉我们,通往更高级别人工智能的道路,必然要求机器超越符号处理,构建起对物理世界更深层次的、多维度的内在理解。从“看懂世界”到“想明世界”,3DThinker迈出了坚实而关键的一步。未来,随着空间智能技术的不断成熟,一个能够真正理解并与我们的三维世界无缝交互的AI时代,正加速到来。
📢💻 【省心锐评】
3DThinker的核心是让AI在思考时“画草图”,用内生的三维想象代替外部工具拼接,实现了从二维描述到三维推理的认知飞跃,是通往物理世界通用AI的关键一步。

评论