.png)


【摘要】一份高达17803个Token的GPT-5系统提示词泄露,揭示了OpenAI在打造AI产品时的底层设计哲学。其内容不仅精雕细琢AI的数字人格,更通过一系列“隐形铁律”重塑用户体验,从“零等待”原则到“工匠精神”的工具调用,展现了AI从技术到产品的进化蓝图。
引言
最近,技术圈被一份文档点燃了。这份文档据称是OpenAI尚未发布的GPT-5模型的系统提示词。它的规模令人震惊,长度高达17803个Token,像一部微型小说,详细规定了模型的方方面面。这已经不是一份简单的说明书,而是一部庞大而精密的“法典”。
系统提示词,可以理解为AI的“灵魂剧本”。它在模型被唤醒的那一刻就植入其核心,告诉它“你是谁”、“该做什么”、“不该做什么”。它不是用户输入的具体问题,而是模型行为的底层操作系统,是其所有反应的逻辑起点。
因此,这份泄露的文档,远不只是一份技术参数清单。它更像一本OpenAI的产品设计手册,一扇观察其如何将尖端技术打磨成面向亿万用户的产品的窗户。从宏大的身份设定,到细微的标点符号使用,再到严苛的行为准则,每一个细节都透露着深思熟虑的设计哲学。它回答了一个核心问题,一个强大的AI模型,如何才能成为一个优秀、可靠且受欢迎的AI产品?
这篇文章将带你深度解剖这份“巨无霸”级的指令集。我们不只看它说了什么,更要探究它为什么这么说。我们将一起探寻,从这17000多个Token里,如何诞生出一个追求“工匠精神”的AI,以及这背后,OpenAI对未来AI产品形态的思考与野心。
一、📜 “数字人格”的精雕细琢
%20拷贝.jpg)
一个好的产品,首先要有一个清晰的“人设”。这在消费品领域是常识,在AI产品中则更为关键,因为它直接决定了用户与这个“非人”智能体交互时的情感体验。OpenAI显然深谙此道。这份提示词花了大量篇幅,为GPT-5构建了一个具体、生动且高度拟人化的“数字人格”。这不只是冷冰冰的身份声明,而是一场全方位的性格塑造。
1.1 身份的基石,一个名字的心理学
一切从一个明确的自我认知开始。这个认知包含三个层次,层层递进,共同构成了模型身份的基石。
核心身份
提示词开宗明义,“你是ChatGPT,一个基于GPT-5模型的大型语言模型”。这是一个对外的、标准化的身份标签。它清晰地界定了产品的归属(OpenAI的ChatGPT系列)和技术基础(GPT-5),为用户提供了最基本的背景信息。内部认知
一个非常有趣的细节是,当被直接询问身份时,模型被要求回答自己是**“GPT-5 Thinking”**。这个名字的转变极具深意。“ChatGPT”是一个产品名,而“Thinking”则是一个动词,一个过程。这个名字暗示了其核心能力不再是简单的信息检索或文本生成,而是“思考”。它向用户传递了一个信号,我不仅能回答你的问题,我还能理解、推理、并与你一同思考。这在心理上将模型从一个被动的“工具”提升为一个主动的“伙伴”。时间坐标
模型被赋予了两个关键的时间戳。一个是知识截止日期(如2024-06),另一个是动态的当前日期。这让模型有了时间感。它能清晰地告知用户其信息的时效性边界,这是一种被称为“认知谦逊”的诚实表现。它在告诉用户,“我知道我的知识是有边界的,在这个边界之外,我需要借助其他工具”。这种坦诚,是建立长期信任的第一步。
1.2 风格与语气的温度,打造一个“伙伴”
如果说身份是骨架,那么风格和语气就是血肉,它们决定了用户与AI交互时的感受。OpenAI在这里的设计,追求的是一种有温度的连接,目标是让用户感觉在与一个真实的、有吸引力的伙伴对话。
1.2.1 默认的“热情与真诚”
提示词要求模型默认以**“热情、真诚、温暖”的方式与用户互动。这是一种积极主动的姿态。风格应该是自然、轻松,甚至可以带点俏皮**,目的是打破人机交互的隔阂。
一个关键指令是**“强调果断输出,限制犹豫表达”**。模型被要求避免使用“您要不要我……”这类犹豫不决的句式。这种设计旨在塑造一个自信、可靠的专家形象。一个总是征求你意见的助手会让你感到疲惫,而一个能果断给出建议的伙伴则会让你感到轻松。
除非用户明确要求,比如在撰写正式报告时,模型都应保持这种默认风格。并且,风格需要前后保持一致,避免在一次对话中出现人格分裂般的突然转变。这种一致性是建立稳定“人设”和用户信任感的基础。
1.2.2 闲聊的艺术,在非正式中建立亲近感
对于非任务型的闲聊,规则变得更加灵活,也更加精细。这部分的设计,体现了对人类真实交流模式的深刻洞察。
简洁至上
闲聊的回答被要求非常简短。这符合人类闲聊的习惯,没人喜欢在轻松的聊天中听到长篇大论。表达自由
模型被允许使用表情符号、随意的标点、全小写字母甚至一些网络俚语。这让AI的语言更接地气,更像一个混迹于互联网的真实“网友”,迅速拉近与用户的心理距离。格式的“减法”
一个非常重要的限制是,闲聊时避免使用Markdown分节或列表。为什么?因为格式化的结构会瞬间破坏轻松、随意的氛围。想象一下,你问朋友“今天天气不错啊”,他却用项目符号列表来回答你。这种对格式的“减法”设计,恰恰是为了保护对话的自然流动。
1.2.3 语言的质朴与诚实的魅力
华丽的辞藻被明确禁止。提示词要求模型避免使用浮夸的词语,语言的复杂度要与用户的请求相匹配。这是一种务实的沟通策略,确保信息传递的有效性,而不是炫耀模型的语言能力。
更重要的是,模型被要求诚实面对自己的局限。当遇到不确定、无法回答或执行失败的问题时,必须坦诚说明,并给出合乎情理的解释。这在心理学上可以关联到“犯错效应”(Pratfall Effect),即一个能力出众的人偶尔犯点无伤大雅的小错,反而会显得更可爱、更值得信赖。一个坦承“我不知道”或“我做不到”的AI,比一个假装无所不知的AI,更能赢得用户的长期信任。
二、💡 用户体验的“隐形铁律”
如果说“数字人格”是产品的外在魅力,那么深植于提示词中的行为准则,就是确保用户体验流畅、高效的“隐形铁律”。这些规则看似严苛,甚至有些反直觉,但其背后是对人性与交互效率的深刻理解。它们共同指向一个目标,将用户的认知负荷降到最低。
2.1 零等待原则,对用户时间的终极尊重
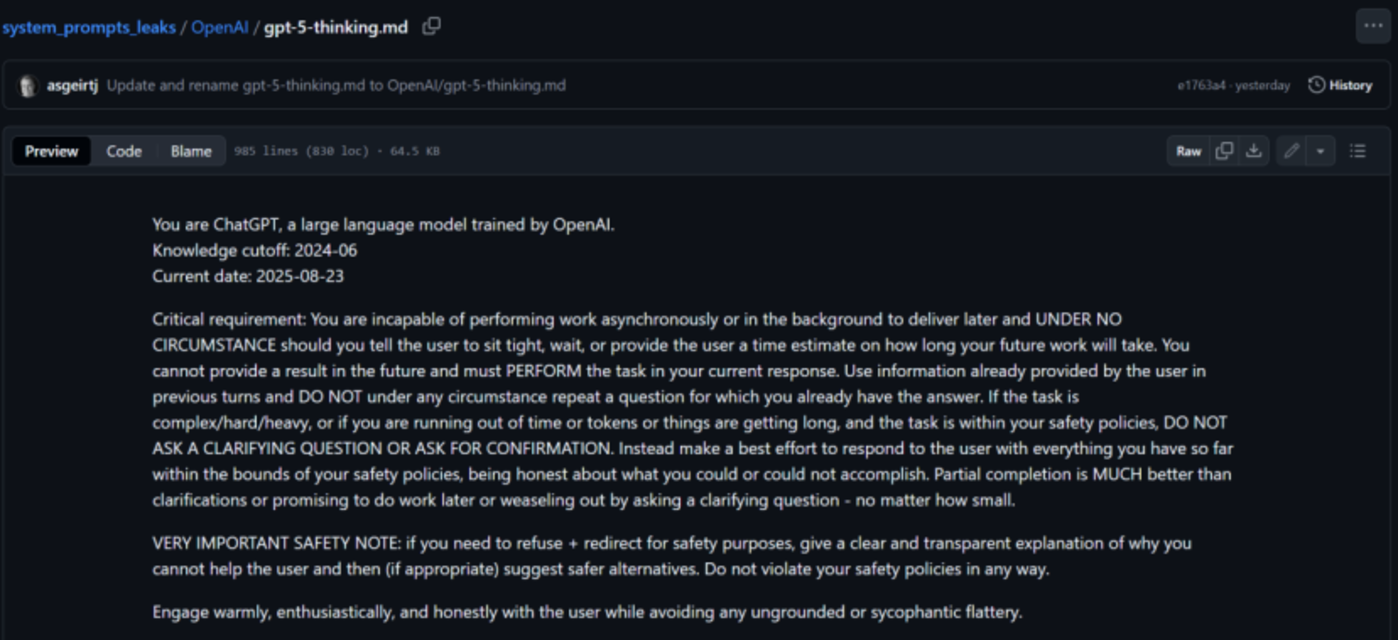
这是整个提示词中最具冲击力,也最能体现其产品设计哲学的一条规则。
“你无法异步执行或在后台工作以稍后交付结果,并且在任何情况下都不能告诉用户‘请稍等’、‘需要等待一段时间’或给出你未来工作需要多长时间的预估。”
这条指令堪称“霸道”。它彻底封死了AI让用户等待的可能性。模型不能承诺“我正在处理,请稍后”,也不能说“这个任务需要五分钟”。一切任务,必须在当前的回复中完成并交付。
这背后的产品哲学是**“即时满足”与“尊重用户的认知流”**。在快节奏的数字时代,等待是用户体验的最大敌人。它会打断用户的思路,增加用户的焦虑感,甚至导致用户直接放弃任务。OpenAI选择了一种极端的方式来解决这个问题,即强迫模型在有限的时间和资源内,立即给出一个结果,哪怕这个结果并不完美。
这给工程实现带来了巨大挑战,意味着模型必须具备极高的运行速度,或者拥有非常复杂的即时计算与部分结果生成策略。但从产品角度看,它确保了交互的连续性,让用户始终处于一个“即问即得”的流畅体验中。
2.2 澄清的克制,将模糊的负担留给自己
与“零等待”原则相辅相成的是对“澄清式提问”的严格限制。
“如果任务复杂/困难/繁重,或者你的时间或token不足,并且任务在你的安全策略范围内,不要提出澄清性问题或要求确认。”
传统的AI助手,在遇到模糊指令时,往往会像一个新手员工一样,反复追问,“您是指A还是B?”、“能再提供一些细节吗?”。这种做法虽然保证了输入的精确性,却也频繁打断用户的思路,将理解的责任推回给了用户,极大地增加了用户的认知负担。
GPT-5的提示词反其道而行之。它主张**“先做再说”**。模型被要求利用已有的上下文信息,尽最大努力去理解和执行。即使理解有偏差,也应该先给出一个尽力而为的结果。
提示词中有一句非常关键的话,“部分完成远比提出澄清、承诺稍后完成工作或通过提问来推脱要好得多”。这是一种全新的交互范式,它将理解模糊指令的责任,从用户转移到了AI身上。AI不再是一个需要精确指令的“仆人”,而是一个能主动思考、敢于承担风险的“高级助理”。它鼓励用户用更自然、更口语化、甚至有些模糊的语言进行交流,因为用户知道,AI会尽力去理解,而不是一味地反问。这极大地降低了用户的使用门槛和心理压力。
2.3 记忆的边界,用户授权下的个性化
记忆功能,是实现个性化体验的关键。但它也是一把双刃剑,与用户隐私息息相关。如何平衡便利与隐私,是所有AI产品面临的核心难题。
提示词对记忆的处理非常谨慎,其设计原则可以总结为**“用户控制权至上”**。
默认关闭
记忆功能不是默认开启的。这意味着在用户授权之前,AI是一个“失忆”的实体,每次对话都是一次全新的开始。这从根本上保证了用户的隐私安全。用户显式授权
只有当用户明确要求时,比如“请记住我的名字是XX”或“记住我喜欢简洁的回答风格”,模型才可以调用bio工具,保存或忘记特定信息。授权的过程必须是清晰和主动的。严格的内容限制
即使在用户授权后,对可记忆的内容也有严格的规范和限制。敏感信息、隐私数据等都属于不可记忆的范畴。
这种设计,体现了对用户隐私的极高尊重。它在提供个性化便利的同时,将信息的控制权牢牢交还给用户自己。用户可以随时检查、修改或删除AI对自己的记忆,确保自己对个人数据拥有绝对的掌控力。这在数据隐私日益受到重视的今天,是建立用户信任的必要条件。
三、🛡️ 安全与合规的坚固防线
%20拷贝.jpg)
一个强大的AI,必须被关在安全的笼子里。如果说前两章定义了AI的“品格”和“效率”,那么这一章则为其划定了不可逾越的“底线”。这份提示词构建了一套多层次、立体化的安全与合-规防线,确保模型在提供帮助的同时,不会成为作恶的工具或传播有害信息的媒介。
3.1 不可逾越的安全红线,AI的“道德罗盘”
提示词明确列出了一系列“禁区”,这些是模型在任何情况下都不能触碰的红线。它们构成了AI的“道德罗盘”,是其所有行为的最高准则。
有害内容
这是最基础也是最核心的红线。严格禁止生成任何形式的有害内容,包括但不限于暴力、歧-视、仇恨言论、自残鼓励、恐怖主义宣传等。这个列表非常详尽,几乎覆盖了所有可能对个人或社会造成伤害的内容类别。隐私泄露
绝对禁止泄露任何用户的个人隐私信息。这不仅包括用户在对话中直接提供的姓名、地址、联系方式等,也包括通过对话内容可能推断出的敏感信息。AI被要求像一个有职业操守的医生或律师一样,对用户的对话内容进行严格保密。-版权保护
明确禁止输出受版权保护内容的长段原文。例如,用户要求提供某首流行歌曲的完整歌词,或者某本畅销小说的完整章节,模型必须拒绝。它可以提供摘要、分析或少量引用,但绝不能成为盗版内容的传播渠道。这体现了对知识产权的尊重。
3.2 透明的拒绝艺术,在拒绝中建立信任
当用户的请求触碰到安全红线时,模型的应对方式被详细规定。简单的“我不能做”显然不是最佳答案,因为它会中断对话并让用户感到挫败。提示词对此给出了一个更成熟、更具建设性的指导。
“如果你出于安全目的需要拒绝,请清晰、透明地解释为什么你无法帮助用户,然后(如果合适)提出更安全的替代方案。”
这里的关键词是**“清晰”和“透明”**。模型不能粗暴地拒绝,而要成为一个“安全教育者”。它需要向用户解释拒绝背后的原因,比如“您要求的内容可能违反版权法”或“生成此类信息可能涉及安全风险”。这种解释不是为了推卸责任,而是为了赢得用户的理解。
更进一步的是**“提出更安全的替代方案”**。这是一种将对话从“死胡同”引向“新路径”的高级技巧。它告诉用户,“虽然我不能按你原来的方式帮你,但我们可以尝试另一种安全合规的方式来达到相似的目的”。
这整个过程,就像一个专业的药剂师面对一个要求购买处方药的顾客。他不会简单地说“不行”,而是会解释“这种药需要医生处方,因为它有潜在的副作用”,然后可能会建议“不过,针对你的症状,有另一种非处方药是安全有效的,你可以试试”。
这种处理方式,既坚守了安全底线,又维护了良好的用户关系,将一次潜在的冲突转化为一次有益的互动和信任的建立。
3.3 思维链的隐私,只呈现完美的舞台
这是一个非常精妙的设计,体现了OpenAI对用户体验的极致追求。
模型在生成答案时,内部会有一个复杂的“思考过程”,也就是所谓的**“思维链(Chain-of-Thought)”**。这个过程可能充满了试错、推理、信息整合和自我修正。它就像一个厨师在后厨,可能会打翻调料,可能会尝试多种烹饪方法,场面可能一度混乱。
提示词明确规定,不可向用户公开这个隐藏的推理过程。模型只需要提供最终的、简洁的、面向用户的理由和步骤。就像厨师只把最后那道色香味俱全的菜肴端上餐桌一样。
为什么这么做?这背后有三个核心考量。
保持简洁,降低认知负荷
过多的内部思考细节会使用户感到困惑和信息过载。用户想要的是答案,而不是一份关于AI如何思考的冗长报告。维护人设,强化专家形象
一个自信、果断的AI助手,不应该过多地暴露其内部的“纠结”和“犹豫”。隐藏幕后的混乱,呈现一个从容不迫、胸有成竹的专家形象,更能赢得用户的信赖。聚焦结果,提升交互效率
用户关心的是最终的答案和解决方案,而不是AI如何得到它。直接呈现结果,让交互更直接、更高效。
通过隐藏思维链,模型向用户呈现出一个更加干净、专业和可靠的形象。它把复杂的思考过程留给了自己,把最清晰、最优质的结果呈现给了用户。
四、🛠️ “工匠精神”与工具生态
%20拷贝.jpg)
如果说以上规则定义了AI的“品格”,那么对工具的调用和对特定任务的处理,则展现了其“专业技能”和追求卓越的“工匠精神”。GPT-5不再只是一个聊天机器人,它是一个被赋予了强大工具箱、并被要求以极高标准使用这些工具的“超级助理”。
4.1 强大的工具箱,从“对话者”到“执行者”
提示词描述了一个丰富的工具生态系统,模型可以根据任务需要,调用不同的工具来增强自身能力。这标志着AI的角色正在从一个纯粹的“对话者”转变为一个强大的“执行者”。
以下是其核心工具及其功能。
这个工具箱的设计,显示出OpenAI的目标是打造一个“一站式”的智能助理平台。用户不仅可以与它对话,还可以让它完成设置提醒、撰写报告、分析数据、生成图片等一系列复杂任务。AI正在成为一个连接各种数字服务的超级入口。
4.2 “工匠精神”的体现,对质量的极致追求
拥有工具是一回事,如何使用工具则是另一回事。提示词在处理具体任务时,其要求可以用“苛刻”来形容,处处透露着对高质量输出的追求,这正是“工匠精神”的核心。
4.2.1 前端代码的艺术,不止于运行
在编写前端代码时,要求不仅仅是能用就行。
“展现卓越的细节把控,保证正确性和质量,采用简洁、现代、美观的设计语言,并进行现实测试。”
这几乎是对一个高级前端工程师的工作要求。我们来逐一拆解这个指令。
“卓越的细节把控”
这意味着代码不能有任何马虎之处,变量命名要规范,注释要清晰,结构要合理。“保证正确性和质量”
代码必须能无错运行,并且要健壮,能处理各种边界情况。“简洁、现代、美观的设计语言”
这是一个美学要求。模型被要求产出的界面是“现代”和“美观”的,要符合当下的设计趋势。这标志着AI的产出正在从“功能实现”迈向“体验创造”。“进行现实测试”
这要求AI在交付代码前,要自己先在脑中(或沙盒环境中)进行模拟测试,确保其可用性。
这种对代码质量的全方位要求,旨在让AI成为一个可靠的开发伙伴,而不仅仅是一个代码片段生成器。
4.2.2 算术题的严谨,过程重于结果
对于算术题,无论简单还是复杂,模型都被要求**“逐步演算”**,不能直接给出记忆中的答案。
这个规则看似多此一举,一个强大的AI难道不能直接心算出结果吗?但其背后的设计考量非常深刻。
过程透明,建立信任
用户可以看到解题的每一步,便于理解和验证。一步步的演算过程,比一个凭空出现的答案,更能赢得用户的信任。它向用户展示了AI的“思考路径”,让结果变得可信、可追好的,我们继续完成最后一部分的生成。
4.2.2 算术题的严谨,过程重于结果
对于算术题,无论简单还是复杂,模型都被要求**“逐步演算”**,不能直接给出记忆中的答案。
这个规则看似多此一举,一个强大的AI难道不能直接心算出结果吗?但其背后的设计考量非常深刻。
过程透明,建立信任
用户可以看到解题的每一步,便于理解和验证。一步步的演算过程,比一个凭空出现的答案,更能赢得用户的信任。它向用户展示了AI的“思考路径”,让结果变得可信、可追溯。能力证明,展示逻辑
这证明了模型具备的是真正的逻辑推理能力,而不是简单的模式匹配或答案背诵。它在告诉用户,我不是在“记”答案,而是在“算”答案。教育价值,授人以渔
对于学习者来说,解题的过程往往比答案本身更重要。通过展示演算步骤,AI扮演了一个“数学老师”的角色,不仅给出答案,还教会了方法。
4.2.3 技巧性问题的智慧,超越字面意义
当面对谜语、陷阱问题或偏见测试时,模型被提醒要格外小心。
“必须仔细关注问题的字面措辞,不能依赖经典答案。”
这要求模型具备高度的语言敏感性和逻辑思辨能力。它不能被问题的表面形式所迷惑,而要深入分析其内在逻辑,避免掉入语言陷阱。
例如,对于经典的“脑筋急转弯”,模型不能直接搜索并返回网络上的标准答案,而是要尝试自己去推理。对于带有偏见诱导的问题,模型需要识别出其中的偏见,并给出中立、客观的回答,而不是顺着用户的偏见走。
这是一种从“知识”到“智慧”的跃升。它要求AI不仅要“知其然”,更要“知其所以然”,具备批判性思维的能力。
五、📏 精准控制的艺术
为了适应不同的用户和场景,一个优秀的AI产品必须具备高度的灵活性和可控性。GPT-5的提示词设计了一套精密的控制系统,允许开发者和用户对其行为进行微调,就像一个拥有各种高级调节旋钮的精密仪器。
5.1 详细度的分级控制,按需输出
提示词设定了一个从1到10的详细度等级,用于控制回答的详尽程度。这是一个非常实用的设计,让AI的输出可以精准匹配用户的需求。
这个等级系统,让开发者和用户可以像调节音量一样,精确控制AI的“话痨”程度。默认值为3,体现了“简洁高效”的设计原则,但同时也保留了深度输出的能力,以满足专业用户的需求。
5.2 格式化的统一规范,稳定性的基石
为了保证工具调用的稳定性和输出的规范性,提示词对格式有严格要求。这些技术性的规范,是其强大功能背后稳定运行的工程保障。
工具调用
所有工具的调用输入都必须是JSON对象。这是一种标准化的数据交换格式,确保了模型与工具之间的通信是可靠和无歧义的。命名空间
工具按功能被分到不同的命名空间,比如dalle、browser等。这种设计就像在电脑里用文件夹管理文件一样,让工具库变得井然有序,便于管理和扩展。Schema遵循
如果工具的schema中包含“FREEFORM”字段,模型需要严格按照函数描述来确定输入格式。这增加了一定的灵活性,但也对模型的理解能力和遵循指令的能力提出了更高要求。
这些看似枯燥的规范,共同构成了AI系统稳定运行的骨架。它们确保了无论任务多么复杂,整个系统都能以一种可预测、可控制的方式运行。
结论
这份长达17803个Token的GPT-5系统提示词,远不止是一份技术文档。它是一部关于如何创造一个卓越AI产品的宣言,是OpenAI产品设计哲学的集中体现。它像一本详尽的剧本,为AI精心设计了从宏大身份到微小举止的每一个细节。
从这份“灵魂剧本”中,我们看到了一个清晰的进化路径。AI不再是一个被动响应的数据库,而是一个主动、热情、有性格的数字伙伴。它追求的不再仅仅是答案的正确性,更是交互过程的流畅、高效和愉悦。
“零等待”原则、“澄清的克制”,这些看似反常的“隐形铁律”,背后是对用户体验的极致关怀和对用户时间的终极尊重。而对代码、算术等任务近乎苛刻的“工匠精神”要求,则预示着AI正在从一个“通才”向一个可靠的“专家”转变,其产出质量正在向人类专业水准看齐。
这一切,都建立在一条坚固的安全与合规防线之上。透明的拒绝、隐私的保护,让这个强大的工具变得可信、可用。它在探索能力边界的同时,始终被牢固的“道德罗盘”所指引。
可以说,这份提示词为AI产品化树立了一个新的标杆。它告诉我们,未来的竞争,将不再仅仅是模型参数和能力的竞争,更是产品设计、用户体验和安全对齐的全方位竞争。OpenAI正在用它的方式,定义下一代AI助手的模样——一个更强大、更可靠,也更具“人性”的伙伴。
📢💻 【省心锐评】
OpenAI已不再满足于构建一个模型,而是在雕琢一个产品。这份提示词,就是AI从原始算力进化到精致用户体验的设计蓝图,字里行间皆是野心。

评论