.png)


【摘要】剖析AI产品从0到1的核心难题,即数据稀疏与用户缺失的双重困境。文章系统阐述了低成本数据获取、小范围用户验证和单点场景聚焦三大实战方法,并提供详尽的操作指南、案例与避坑建议,旨在帮助团队突破冷启动僵局,启动价值增长飞轮。
引言
投身AI产品开发,几乎每个团队都会撞上一堵名为“冷启动”的墙。这堵墙由几个坚硬的砖块砌成,用户认知门槛高,场景教育成本大,数据反馈滞后。许多充满希望的项目,就在这0到1的征途上,悄然陷入停滞。
我们都熟悉那种尴尬。想训练一个基础的意图识别模型,翻遍家底只有几百条零散的用户对话。好不容易搭出产品雏形,费尽心力也只找到几十个愿意尝鲜的用户。最糟糕的情况是,这稀少的数据导致模型表现不佳,用户体验一次便失望离去,再不回头。于是,产品陷入了那个经典的“死亡螺旋”——数据少导致效果差,效果差导致用户少,用户少导致数据更少。
很多人将破局的希望寄托于“等”。等数据积累足够,等用户规模上来,等资源配置到位。但对于绝大多数身处激烈竞争中的团队而言,等待等同于慢性自杀。
冷启动的本质,并非被动等待,而是主动创造条件。它不是一场资源的比拼,而是一场关于智慧、策略与执行力的考验。它要求我们用最低的成本,凑齐能让模型跑起来的“燃料”;用最小的范围,验证模型能创造的真实价值;用最准的切点,撕开市场的一道缺口。
这篇文章不谈空泛的理论。我们将深入实战,拆解三个经过反复验证的破局方法。从数据、用户到场景,一步步带你构建AI产品的增长引擎,帮你找到撬动地球的那第一根杠杆。
🎯 一、低成本数据获取,从“借”与“造”双管齐下
%20拷贝-abtt.jpg)
AI的智慧源于数据,这是业界的共识。但在冷启动阶段,数据恰恰是最稀缺的资源。一个普遍的误区是,必须拥有成千上万条高质量标注数据,才能启动模型训练。实际上,这是一种理想化的奢望。聪明的团队懂得如何“无米之炊”,通过“借”和“造”两种手段,快速构建起一个虽不完美但可用的最小数据集。
1.1 “借”数据,挖掘外部世界的宝藏
“借”数据的核心思路,是利用现有的公开或半公开资源,通过迁移学习(Transfer Learning) 的思想,将外部知识快速引入自己的模型。关键在于“精准筛选”,而非盲目堆砌。
1.1.1 优先锁定高匹配度的公开资源
互联网上散落着海量的数据金矿,等待有心人去挖掘。Hugging Face、天池、Kaggle、GitHub Awesome Datasets等平台,都是不错的起点。
以一个电商AI客服项目为例,冷启动需要大量的“用户咨询-客服回复”对话数据。完全从零开始积累,无异于天方夜谭。正确的做法是分步走。
第一步,定向搜索垂直领域数据集。在Hugging Face Hub上,可以搜索“电商客服”、“FAQ”、“对话”等关键词,筛选出如“电商客服FAQ数据集”、“物流咨询对话集”等。
第二步,进行场景匹配与数据清洗。这是“借”数据中最耗费心力,也最体现专业度的一环。假设你的产品服务于美妆电商,那么下载的数据集中,与家电、3C数码相关的客服对话就必须剔除。同时,数据具有时效性,三年前的售后规则、活动政策早已失效,需要通过规则或人工方式清洗掉这些“过时内容”。经过这一轮精细操作,通常能获得1000到2000条可用的基础对话数据。
第三步,拓展非直接竞争者的公开信息源。除了专业数据集,同行业非竞争对手的公开资料也是宝库。比如,一个开发AI错题本的团队,可以从各大教育类公众号、知名中学的官网、在线教育平台的公开课讲义中,提取大量的“题目+典型错误+正确解析”样本。这些数据虽然格式不一,量可能不大,但胜在高度精准和贴近真实场景。
下面是一个“借”数据的通用操作流程,可以作为团队的行动清单。
1.1.2 同步留存第三方API的交互数据
在产品初期,很多团队会选择集成成熟的第三方AI服务来快速实现功能,比如使用阿里云小蜜、腾讯云智能客服等。这不仅是功能的捷径,更是数据的捷径。
当你的产品通过API调用这些服务时,每一次交互都是一次宝贵的数据沉淀。你需要做的,就是建立一个简单的日志系统,将API的请求和返回完整地记录下来。
以客服机器人为例,每次用户与机器人对话,API通常会返回一个包含以下信息的JSON对象。
{
"session_id": "sid_123456789",
"user_query": "我的订单什么时候能到?",
"bot_reply": "请提供您的订单号,以便我为您查询物流信息。",
"intent": "query_logistics",
"confidence": 0.92,
"is_fallback": false, // 是否未能识别意图
"is_transfer_to_human": false // 是否建议转人工
}
你需要做的,就是将这些记录,特别是user_query、bot_reply以及后续是否真的is_transfer_to_human等关键信息,存储到你的数据库中。这样,即便每天只有几十个用户,一周也能积累数百条完全源于真实业务场景的高价值数据。这些数据远比任何公开数据集都更贴合你的用户和业务,是后续模型自研或优化的基石。
1.2 “造”数据,用智慧弥补数量的不足
当“借”来的数据仍然无法满足核心场景的启动需求时,我们就需要亲自动手“造”数据。这里的“造”,并非凭空捏造,而是基于专家知识和规则,有目的地生成高质量数据。其核心是数据增强(Data Augmentation) 和 合成数据(Synthetic Data) 的应用。
1.2.1 人工标注核心样本,注入专家知识
在模型训练的最初阶段,质远比量重要。与其拥有10000条低质量的自动抓取数据,不如拥有200条覆盖了核心场景的高质量人工标注数据。
我们以AI意图识别为例,假设初期需要模型能准确区分“查订单”、“查物流”、“售后投诉”这三个核心意图。一个高效的做法是,团队的产品、运营或客服人员,每人每天花1小时,手写或整理出覆盖这三个意图的典型用户问法。
这个过程不需要复杂的标注工具,一个Excel表格就足够了。
通过这种方式,一个3人小组,每天投入少量时间,一周就能轻松积累数百条包含各种表述方式、错别字、方言口语的核心样本。这些样本是模型的“启蒙老师”,能帮助它快速建立对核心业务场景的基本认知。这个过程,本质上是一种专家知识注入,将团队对业务的理解,直接传递给模型。
1.2.2 规则生成合成数据,实现规模化补充
当核心样本覆盖了“点”,我们还需要用合成数据来扩展“面”,帮助模型学习通用的模式和格式。
以AI商品标题生成工具为例。一个好的商品标题通常遵循一定的范式。我们可以先定义出这个范式。
标题规则 [品牌] + [品类] + [核心卖点1] + [核心卖点2] + [适用人群/季节] + [规格]
然后,为每个部分准备一个词库。
品牌
[A品牌, B品牌, C品牌]品类
[连衣裙, T恤, 牛仔裤]核心卖点1
[碎花, 纯色, 条纹]核心卖点2
[显瘦, 收腰, V领]适用季节
[夏季, 新款, 2024]规格
[S码, 均码]
接下来,利用简单的脚本或Excel的公式,就可以将这些元素排列组合,批量生成成千上万条符合基本格式的标题样本。比如 “A品牌 夏季新款 碎花连衣裙 显瘦收腰 S码”。
虽然这些数据是“合成”的,缺乏真实世界的多样性,但它们对于冷启动阶段的模型有两个巨大好处。
学习基础结构。模型能快速掌握一个合格标题应该包含哪些元素,以及它们的通常顺序。
扩充词汇量。模型能认识到“碎花”、“显瘦”是描述“连衣裙”的常见词汇。
更进一步,我们还可以利用大语言模型(LLM)来生成更多样化的合成数据。比如,给LLM一个指令。
“你是一个专业的电商文案。请根据以下核心词,生成10个不同风格的商品标题,核心词是:连衣裙,夏季,碎花。”
LLM可能会生成包括“法式复古碎花连衣裙,解锁你的夏日浪漫”、“清凉一夏,这款碎花连衣裙是衣柜必备”等更多样化的标题。这比简单的规则拼接质量更高。
通过“借”与“造”的结合,一个资源有限的小团队,完全可以在一到两周内,从零开始构建起一个包含数千条数据的初始训练集,足以支撑一个最小可用模型(Minimum Viable Model)的诞生。
1.3 案例融合,看SaaS小团队如何凑齐第一桶“数据金”
让我们来看一个真实的精简案例。
一个10人规模的SaaS公司,计划推出一款面向中小商家的AI客服工具。启动时,他们手里只有不到300条零散的历史对话记录,远远不够。
他们的策略如下。
借。团队花了两天时间,从公开数据平台下载了多个“中小电商客服FAQ数据集”,经过筛选、去重和合并,整理出约1500条对话。接着,他们又花了一天,编写脚本,将其中涉及的品牌名、特定优惠活动(如“双十一大促”)替换为更通用的占位符,或适配他们目标客户常用的规则(比如把“7天无理由退货”批量修改为“15天无理由包换”)。最终,获得了800条高质量的适配后对话。
造。团队动员了公司内部的3名客服人员,要求他们利用工作间隙,每天整理并标注20条“棘手”的用户提问。这些提问重点覆盖了用户使用方言、带有错别字、一句话包含多个意图等边缘但高频的场景。3天时间,他们就积累了
3人 * 20条/天 * 3天 = 180条极具价值的核心样本。
最终,他们用这 300 (原始) + 800 (借) + 180 (造) = 1280 条数据,训练出了第一版意图识别模型。虽然在内部测试中,模型的准确率只有75%左右,但这已经足够支撑产品进入下一个阶段——小范围用户验证。他们没有等待“完美”的数据,而是主动创造了“可用”的数据,为产品的冷启动赢得了宝贵的时间。
🚀 二、小范围用户验证,用精准反馈点燃增长引擎
数据问题初步解决后,产品雏形诞生。此时,另一个巨大的诱惑摆在面前,是否要进行大规模推广,快速获取用户?答案是否定的。在模型尚不成熟、产品体验存在诸多未知的情况下,盲目推广无异于将一个半成品推向战场,结果只会是用户的快速流失和口碑的崩塌。
冷启动阶段的用户验证,追求的不是“量”,而是“质”。核心目标是找到10到50个精准的种子用户,与他们建立一个高效、闭环的反馈机制,通过“试用 → 反馈 → 调优”的循环,将模型从“勉强能跑”打磨到“确实有用”。这个过程,是启动AI产品“数据飞轮”的第一推动力。
2.1 选对种子用户,让每一次反馈都价值千金
种子用户的选择,是冷启动用户验证成败的关键。他们不是普通的用户,而是你产品早期的“共建者”。一个好的种子用户,远胜过一百个沉默的普通用户。理想的种子用户通常具备两个核心特质。
高需求度。他们对你的产品所要解决的问题有强烈的痛点,是天然的目标用户。比如,开发一款AI辅助编程工具,种子用户应该是每天编写大量代码的程序员,而不是偶尔写脚本的产品经理。需求越真实,他们使用产品的动力越足,提供的反馈也越贴近实际场景。
高反馈意愿。他们乐于分享、善于表达,并且愿意投入时间帮助你改进产品。这类用户通常可以从以下几个渠道寻找。
内部员工。尤其是与产品目标用户画像一致的同事(如市场部的同事试用AI文案工具)。他们沟通成本低,反馈直接。
行业社群的活跃分子。在相关的微信群、知识星球、技术论坛里,总有一些乐于尝鲜、指点江山的“意见领袖”。主动联系他们,提供免费试用资格,往往能收获意想不到的深度见解。
个人网络。你的朋友、前同事、校友中,可能就隐藏着最完美的种子用户。
一个AI文案生成工具的冷启动团队,就精准地选择了两类种子用户。一类是公司内部的市场部同事,他们每天都要为公众号、社交媒体撰写文案,需求刚性。另一类是在一个垂直电商卖家社群里招募的10个小商家,他们渴望用更低的成本解决商品文案的撰写难题,反馈意愿极强。这两类用户加起来总共才15人,但他们提出的问题却刀刀见血,比如“生成的文案太官方,不够口语化”、“希望增加一个专门生成小红书风格文案的模式”、“能否在生成时自动带上促销信息”。这些具体而可执行的反馈,为产品迭代指明了清晰的方向。
下面是一个种子用户筛选的评估模型,可以帮助你更科学地做出选择。
2.2 设计轻量反馈闭环,让用户“随手”就能提意见
找到了对的种子用户,下一步是建立一个让他们能够轻松、无压力地提供反馈的渠道。冷启动阶段的用户耐心有限,复杂的问卷、冗长的访谈都会让他们望而却步。反馈机制的设计,必须遵循“轻量、即时、直接”的原则。
2.2.1 三种有效的轻量化反馈方式
即时反馈组件(Thumbs Up/Down)。这是最常见也最有效的方式。在AI生成内容的旁边,放置一对“赞”和“踩”的按钮。用户点击后,可以弹出一个非必填的简短追问。
点击“赞”,追问可以是“本次结果好在哪里?(可选)”。
点击“踩”,追问必须更具体,最好是选择题形式,如“不满意的原因是?[ ] 风格不对 [ ] 事实错误 [ ] 格式混乱 [ ] 其他(请填写)”。
这种方式将反馈的动作成本降到最低,同时能快速收集到大量关于单次生成结果的结构化数据。
1对1的“咖啡时间”访谈。每周固定时间,邀请2-3名最活跃的种子用户,进行15-20分钟的线上快速访谈。访谈不求全面,只聚焦于几个核心问题。
“上周你主要用这个功能做了什么?”(验证使用场景)
“哪个瞬间让你觉得‘这个功能还挺好用’?”(挖掘Aha Moment)
“哪一步操作让你觉得特别不顺畅,或者想骂人?”(定位核心痛点)
“如果让你给产品提一个最重要的建议,会是什么?”(明确迭代优先级)
这种短平快的沟通,比长篇大论的正式访谈,更能获得真实、鲜活的用户心声。
专属反馈微信群。创建一个种子用户专属的微信群,产品经理、核心研发人员都在群里。规定好群规则,鼓励用户随时遇到问题,随时截图、录屏发到群里。团队成员需要做到当天问题当天响应,即便不能立刻解决,也要告知用户“问题已收到,我们正在分析”。这种高响应度的服务,会让种子用户感受到被尊重,从而更愿意持续提供高质量反馈。
2.2.2 技术与流程的结合,实现主动学习
在技术层面,这个反馈闭环可以与主动学习(Active Learning) 机制深度结合。主动学习的核心思想是,让模型自己“承认”它对哪些输入感到“困惑”,然后主动将这些“疑难杂症”推送给人类专家(即种子用户)进行标注。
下面是主动学习反馈闭环的简化流程。
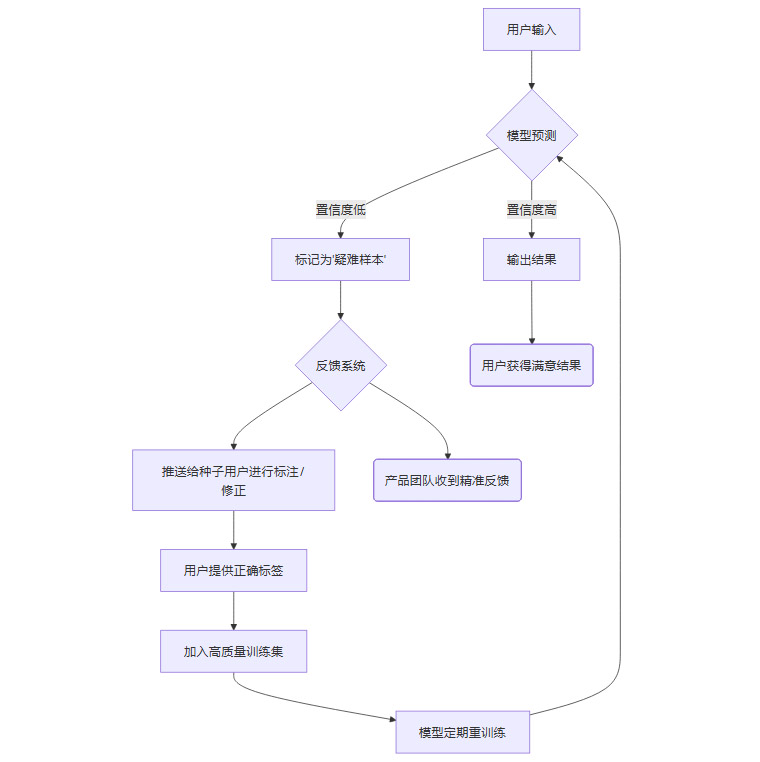
这个流程不仅解决了用户的即时问题,更重要的是,它让最有价值的反馈数据,自动流入了训练管道,形成了一个自我优化的智能系统。
2.3 快速调优,用“小步快跑”代替“完美主义”
收集到反馈后,最忌讳的是“攒着”。“等我们收集到足够多的同类问题再一起改吧”,这种想法在冷启动阶段是致命的。种子用户数量少,他们的耐心更宝贵。每一次有效的反馈,都应该被视为一次迭代的冲锋号。
小步快跑,快速迭代,是这一阶段的核心行动准则。
一个做AI客服的团队,在冷启动时收到了种子用户的反馈,“我问‘怎么退定金’,机器人总是错误地识别为‘查订单’,然后回复我查订单的流程,完全不对。”
传统的大公司流程可能是,产品经理记录问题,写入需求池,排期,等待下个迭代周期。但这个小团队的做法是,产品经理当天下午就拉着算法工程师,在标注后台紧急新增了一个“退定金”的意图标签,并手动补充了10条相关的问法样本(如“定金能退吗”、“不想买了,退我定金”等)。然后,他们当晚就重新训练了模型,第二天一早就部署了新版本,并立刻在反馈群里@那位用户,“您昨天反馈的问题我们优化了,麻烦再试一下,看看现在是否正确?”
这种极致的响应速度和迭代效率,给种子用户带来了巨大的惊喜和参与感。他们会觉得,自己的声音真的被听到了,自己的意见真的在推动产品变好。
再比如,一个AI商品推荐工具,初期模型效果不佳,用户抱怨“推荐的商品和我的需求完全不匹配”。团队没有选择耗时数周去大改复杂的推荐模型,而是做了一个简单的“曲线救国”方案。他们在推荐页的顶部,增加了一个“手动选择偏好品类”的按钮。用户可以先手动选择“女装→连衣裙→碎花风”,然后AI再基于这个已经缩小的范围进行推荐。虽然不够“智能”,但用户满意度立刻大幅提升。这个简单的功能补丁,为团队赢得了宝贵的时间,去收集更多用户行为数据,从而在未来真正优化好推荐模型。
2.4 案例融合,看教育AI如何跑通验证闭环
一个开发初中数学AI错题本的小团队,初期只有3位合作中学的数学老师作为种子用户。他们用三周时间,完美演绎了小范围用户验证的全过程。
第一周,聚焦核心功能,快速响应。老师们使用后,普遍反馈“几何题的错误原因分析太笼通了,总是说‘知识点掌握不牢’,没有具体指出是哪个知识点。” 团队收到反馈后,当天就组织人手,专门针对初中几何的常见错误,补充了20条更细致的错误原因样本,比如“全等三角形判定条件SAS与SSA混淆”、“辅助线作法错误导致无法证明”等。第二天,模型更新,老师们立刻感受到了分析质量的提升。
第二周,用“笨办法”满足用户“巧需求”。一位老师提出,“我希望能把每周的班级高频错题导出到Excel,方便我打印出来在课堂上讲解。” 团队评估后发现,做一个完善的、带各种自定义选项的导出功能,至少需要一周开发时间。他们决定走捷径,产品经理直接对老师说,“这个功能我们记下了,正在规划。在这之前,您每周五把需要导出的错题发给我,我用脚本帮您手动处理,半小时内发给您Excel文件。” 这个看似“笨拙”的解决方案,却以极低的成本满足了用户的核心需求,赢得了老师的赞誉。
第三周,实现口碑裂变,用户自然增长。由于产品体验持续优化,服务响应又快又好,其中一位老师主动将这个工具推荐给了同校的5位同事。团队的种子用户,就这样从3个自然增长到了8个。随着更多错题数据的汇入,模型的分析准确率也从最初的70%稳步提升到了82%。一个正向的、可持续的增长闭环,就这样慢慢跑通了。
💎 三、场景聚焦,用单点突破撬动全面胜利
%20拷贝-oxzk.jpg)
许多雄心勃勃的AI产品,在冷启动阶段就折戟沉沙,其根源往往在于一个致命的错误——贪多求全。团队试图从第一天起,就打造一个无所不能的“全功能平台”。比如,一个面向电商的AI工具,既想做智能客服,又想做个性化推荐,还想涉足供应链选品。结果是,资源被极度分散,每个功能都因为数据不足、优化不够而体验糟糕,最终一事无成。
AI技术的落地,遵循着一个从“点”到“线”再到“面”的普遍规律。冷启动的智慧,恰恰在于克制。你需要抵制住构建宏大蓝图的诱惑,将所有资源聚焦于一个高频、低门槛的单点场景,将其打磨成一把锋利的匕首,先撕开市场的坚固防线。先做成一个“小而美”的工具,再图谋“大而全”的平台。
3.1 如何选择那个决定生死的“单点场景”?
一个理想的冷启动切入场景,必须同时满足两个核心条件。
高频(High Frequency)。用户会频繁地遇到这个场景,使用你的工具。高频意味着更多的使用次数,更多的使用次数意味着更多的数据回流和更快的模型迭代速度。对于电商商家而言,每天处理售后问题、回复用户咨询、撰写商品标题,都是高频场景。而店铺装修、年度盘点,则是典型的低频场景。
低门槛(Low Barrier)。用户理解和使用这个功能的成本要足够低。一个好的单点工具,应该像一个计算器,用户输入简单的指令,就能立刻获得明确的结果。AI商品标题生成工具就是个很好的例子,商家只需输入“女装、夏季、碎花”等几个关键词,就能得到一串可用的标题。相比之下,“AI智能选品”工具的门槛就高得多,它可能需要商家填写复杂的店铺数据、目标人群画像、预算限制等一系列参数,让很多中小商家望而却步。
下面是一个用于评估候选单点场景的决策矩阵,可以帮助团队进行更理性的选择。
从上表可以看出,“AI商品标题生成”、“AI会议纪要提取”和“AI智能客服”中的“物流查询”子场景,都是非常理想的冷启动切入点。它们都具备高频、低门槛的特性,能让产品快速启动价值循环。
一个AI办公工具的团队,在冷启动时就做出了明智的选择。他们没有一开始就去做复杂的“AI项目管理”或“AI日程自动编排”,而是只聚焦于一个极其具体的需求——会议纪要自动提取重点。用户只需上传会议录音,AI就能自动输出一份包含“待办事项(Action Items)”和“核心结论(Key Decisions)”的精简纪要。这个功能精准地击中了大量职场人士“开会两小时,整理纪要一下午”的痛点,迅速吸引了一批忠实的早期用户。
3.2 用单点场景,悄然积累最宝贵的两大资产
一个成功的单点工具,虽然功能简单,但它能为团队带来两样无价之宝。
结构化的用户行为数据。当用户持续使用你的单点工具时,他们就在不知不觉中,为你进行着“数据标注”。
在使用AI标题生成工具时,用户输入了哪些核心词,最终选择了哪个AI生成的标题,或者在哪个标题的基础上进行了修改。这些行为数据,构成了大量高质量的
(输入属性) -> (优质标题)的配对数据。在使用AI会议纪要工具时,用户是否采纳了AI提取的“待办事项”,是否手动修正或补充了“核心结论”。这些都是优化模型理解能力和摘要能力的宝贵信号。
来之不易的用户信任。当用户发现,你这个小工具确实帮助他们解决了某个具体问题,节省了时间,提升了效率时,他们对你的产品和团队的信任感便开始建立。这种信任,是未来你推出更复杂、更高价值功能时,用户愿意尝试和付费的基础。信任一旦建立,用户留存和转化率都会显著提高。
一个电商AI团队的成长路径完美诠释了这一点。他们冷启动时,只提供一个“AI标题优化”的免费小工具。半年时间里,他们凭借这个小工具,积累了超过500个活跃的商家用户和近2万条高质量的标题优化数据。当他们半年后推出付费的“AI详情页一键生成”功能时,有超过30%的老用户在第一时间就付费试用。他们几乎没有花费任何额外的营销成本,就完成了新功能的冷启动。这就是单点突破带来的复利效应。
3.3 从“单点”到“场景链”,规划你的扩张路径
当你的单点工具已经跑通,拥有了一批忠实用户和稳定的数据回流后,就可以开始规划下一步的扩张了。扩张的路径不应是跳跃式的,而应是沿着用户工作流的自然延伸,形成一条环环相扣的“场景链”。
以“AI标题生成”工具为例,其后续的扩张路径可以这样规划。
第一步,扩展到紧密关联的场景。用户写完标题,下一步通常是做什么?是设计主图和撰写主图文案。那么,下一个功能就可以是“标题与主图文案智能匹配”。AI可以根据已经生成的优质标题,推荐或生成与之风格、卖点一致的主图文案。
第二步,延伸到工作流的下游场景。有了标题和主图文案,商家可能需要考虑商品推荐。于是,可以推出“基于标题与文案的相似商品推荐”功能,帮助商家在商品详情页设置关联销售。
第三步,向上游或更复杂的场景探索。当产品已经深入商家的日常运营后,可以尝试推出更高价值的复杂功能,如“基于全店商品数据和市场趋势的AI选品建议”。
这条从“点”(标题生成)到“线”(标题+文案+推荐)再到“面”(全链路电商运营助手)的扩张路径,每一步都建立在前一步积累的用户和数据之上,风险更低,成功率更高。
同样,一个AI客服工具,可以从最简单、最高频的“物流查询”场景切入。当这个场景的识别率和解决率做到极致后,再逐步扩展到“订单状态修改”、“优惠券使用咨询”、“售后退换货申请”等更复杂的场景。最终,才能成长为一个能处理绝大多数问题的全场景智能客服平台。
🚧 四、冷启动必须绕开的三个“坑”
%20拷贝-hrzc.jpg)
理论和方法都已清晰,但在实际执行中,依然有几个常见的“坑”需要我们时刻警惕。绕开它们,你的冷启动之路会平坦许多。
贪多求全的“平台梦”。再次强调,冷启动阶段,“一项精通”远胜于“十项全能”。如果你的AI客服同时上线“物流查询”、“售后投诉”、“商品咨询”三个场景,但每个场景的数据都很少,模型效果都只有60分,用户体验会是灾难性的。正确的做法是,集中所有资源,先把“物流查询”这个场景的回复准确率做到85%以上,让用户在这个点上建立起绝对的信任,然后再去啃下一块硬骨头。
对AI过度自信,忽视“人工兜底”。冷启动阶段的模型,必然是不完美的。承认这一点,并为它的不完美准备好“安全网”,是产品成熟度的体现。AI不行时,人工必须补位。
AI客服。当机器人连续两次无法理解用户问题,或用户明确提出“转人工”时,必须提供一个一键转接人工客服的清晰入口。
AI内容生成。对于一些关键内容,如具有法律效力的合同草案、面向重要客户的营销邮件,AI生成后必须经过人工审核环节才能正式发出。
AI识别。一个AI人脸考勤工具,在冷启动时对戴口罩的识别率可能不高。此时,必须提供一个“打卡异常,申请人工确认”的按钮,避免用户因为技术问题而无法正常打卡。人工兜底不仅是体验的保障,更是收集模型失败案例、进行针对性优化的重要途径。
追求完美的“上线拖延症”。很多技术背景的团队,都有着一种“工程师式的完美主义”。他们觉得,“模型准确率不到90%就不能上线,否则就是对用户不负责任”。这种想法在学术界或许值得尊敬,但在商业世界却是致命的。冷启动阶段,70%的准确率,只要能为用户创造哪怕一点点价值,就值得上线。
一个AI文案生成工具,即使生成的文案有30%需要用户手动修改,但如果它能帮助用户将撰写时间从1小时缩短到30分钟,那么它对于用户来说就是有价值的。
更重要的是,那30%被用户修改过的数据,恰恰是优化模型最宝贵的“养料”。用户修改的过程,就是在告诉模型“你这里写得不对,应该这样写才更好”。上线后获得的真实交互数据,是任何模拟数据都无法替代的。
结语
AI产品的冷启动,是一场在资源稀缺的荒原上,点燃第一簇篝火的艰难旅程。它的核心,不是被动地等待风来,而是主动地去寻找火种,搭建灶台,并小心翼翼地守护火苗,直到它足以燎原。
回顾全文,我们拆解了三大核心战术。
数据层面,我们不再枯等,而是主动出击,通过“借”外部资源和“造”核心样本,快速构建最小可用数据集。
用户层面,我们放弃广撒网,转而聚焦于一小群精准的种子用户,与他们建立高效的反馈闭环,用真实的需求驱动产品迭代。
场景层面,我们克制住构建宏大平台的冲动,选择一个高频、低门槛的单点场景进行深度打磨,以此为支点,撬动更广阔的市场。
对于身处其中的产品经理和开发者而言,冷启动阶段最宝贵的品质,或许不是高深的技术能力,而是那种在约束中寻找最优解的灵活智慧。没有海量数据,就用小样本和规则跑出基础模型;没有大量用户,就和10个铁杆粉丝一起打磨产品;没有全功能,就用一个惊艳的单点工具赢得最初的喝彩。
只要你的产品,能在哪怕一个极小的范围内,为一小部分人,创造出真实、可感知的价值,那么,冷启动最艰难的一步,便已成功迈出。剩下的,就是沿着这条被验证的路径,坚定而耐心地走下去,让数据的飞轮越转越快,让价值的雪球越滚越大。
📢💻 【省心锐评】
冷启动的本质是价值验证,而非功能堆砌。与其空想一个完美的AI平台,不如先动手解决一个真实的小问题。用最小成本跑通数据、用户、场景的闭环,才是活下去的唯一法则。

评论