.png)


【摘要】本文系统梳理《大模型应用中间件通用技术要求》标准,深度剖析其技术架构、创新机制、刚性要求、行业落地与未来演进,结合权威数据与案例,全面展现AI中间件标准化对产业智能化的深远影响。
🏁引言:大模型落地的困局与标准化破局之道
2023年,全球大模型数量已突破300个(斯坦福AI指数报告),但企业级应用渗透率却不足15%(IDC数据)。大模型技术的飞速发展与企业实际落地之间,存在着巨大的“断层”——模型能力强大,却难以高效、安全、低成本地服务于千行百业。企业普遍面临如下三大核心矛盾:
集成复杂度高:不同模型接口标准不一,跨系统协同难度大,导致开发周期长、维护成本高。
垂类开发门槛高:行业数据训练与微调成本动辄百万级,缺乏高效的模型适配与复用机制。
安全风险突出:60%企业担忧敏感数据泄露,合规与可追溯性成为AI应用的“生命线”。
在此背景下,《大模型应用中间件通用技术要求》标准的发布,标志着AI产业从“野蛮生长”迈入“标准化基建”时代。它不仅为大模型应用提供了“施工图”,更是企业智能化转型的“说明书”,为AI大规模落地扫清障碍。
🏗️标准的背景和概述
《大模型应用中间件通用技术要求》由南方电网电力科技、广州运通链达金服牵头,联合多家龙头企业和专家团队,制定并发布了国内首个团体标准。该标准不仅填补了行业空白,更为企业数字化转型和AI落地提供了系统化的“说明书”和“施工图”,成为推动大模型技术规模化应用的基石。其制定过程汇聚了电力、金融、制造、医疗、教育、信息安全等多个行业的顶尖企业和专家,充分吸收了各行业在大模型应用落地过程中的真实需求和最佳实践。
标准的发布,填补了国内大模型中间件领域的标准空白,为企业构建垂类大模型应用、微调训练、AI驱动业务创新、集成大模型与企业内外部信息系统提供了权威的技术规范和操作指南。它不仅为企业数字化转型提供了坚实的技术底座,也为大模型产业生态的健康发展奠定了基础。
标准的核心目标在于:
降低企业应用大模型的技术和成本门槛,提升垂类大模型开发效率。
支持大模型的私有化部署,保护企业数据安全和数据资产。
促进开源和商业多模态大模型的开放与互联,推动AI能力与企业业务的深度融合。
为大模型应用的安全、合规、可追溯提供全流程保障。
标准的制定和实施,标志着中国在大模型中间件领域迈出了关键一步,为全球AI产业的标准化进程贡献了中国智慧和中国方案。
在后续章节中,将详细解析该标准的技术架构、创新机制、刚性要求、行业落地、开发实践与未来展望,帮助读者全面理解和把握大模型中间件标准化的深远意义和实际价值。
🏗️技术全景:九大模块构建AI“操作系统”
1️⃣ 大模型中间件定义
大模型应用中间件系统应介于大模型应用与大模型及数据源之间,给企业大模型应用开发起到桥梁作用。
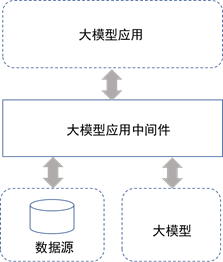
大模型应用中间件系统边界图
2️⃣ 架构总览
标准定义了大模型应用中间件的九大核心模块,形成数据、智能、模型、安全、监控的全流程闭环:
数据接口:对接SQL/NoSQL/图数据库及多种文件格式,打通数据孤岛。
数据处理:支持多源数据加载、转换、向量化、结构化,适配多模态需求。
数据检索:高效向量/图数据库检索,支撑10亿级数据毫秒级响应。
模型接口:兼容主流商用/开源大模型,支持动态加载/卸载与多模态输入输出。
智能体:任务规划、工具调用、自我纠错,支持COT/TOT/ReAct等智能体框架。
应用接口:标准化API,覆盖对话、绘图、视频、图文等多模态场景。
模型训练:支持Lora/PEFT微调、全量/部分参数训练、强化学习等多种训练范式。
安全与审计:身份认证、权限管理、敏感词过滤、区块链存证,保障全链路安全合规。
监控与评测:实时监控、性能评测、智能告警,保障系统稳定与可用性。
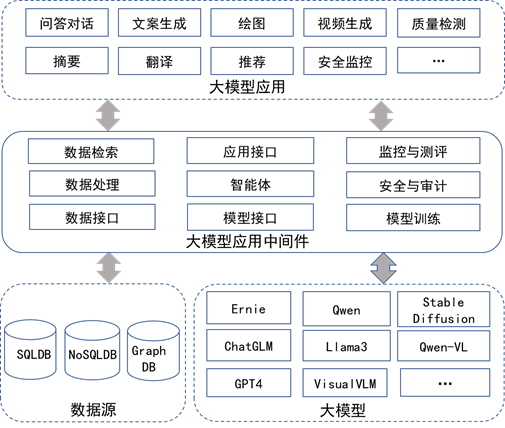
系统总体架构图
3️⃣ 模块功能与技术要求
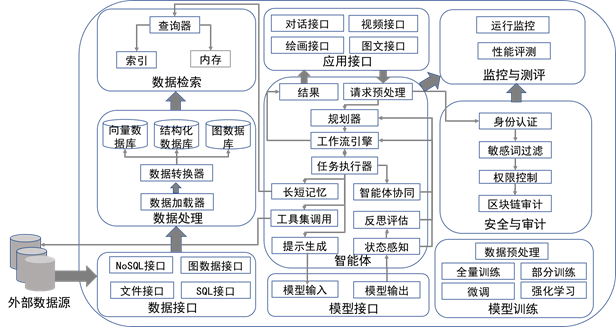
大模型应用中间件组件架构图
🚀五大创新机制:重塑AI开发范式
1️⃣ 智能体:从“人工编程”到“自主进化”
任务拆解与动态调度:用户输入“生成Q3市场报告”,系统自动拆解为数据收集、分析、生成、校验四阶段,智能体动态调用CRM、Stable Diffusion、GPT-4等多工具协同作业。
反思机制:如报告数据矛盾,自动二次校验,持续优化输出。
案例成效:某金融客户报告生成时效从8小时缩短至20分钟。
2️⃣ 模型训练:低成本打造行业专属大脑
高效微调:Lora技术将训练成本降至1/10,7B模型仅需2张A100显卡。
强化学习对齐:DPO算法让模型输出合规性提升35%。
一键部署:支持百GB级数据集自动清洗、格式转换与分割。
3️⃣ 安全合规:构建可信AI“防护网”
数据加密:端到端TLS/SSL+国密算法双重保障。
权限管控:6级角色权限体系,字段级数据隔离。
区块链审计:关键操作上链存证,支持司法溯源。
4️⃣ 性能突破:工业级稳定性保障
高并发低延迟:100并发下P99延迟≤5秒,超金融交易系统标准。
故障自愈:模型服务异常30秒内自动切换备用实例。
资源调度:GPU利用率提升至85%以上。
5️⃣ 生态互联:打破AI“孤岛效应”
接口标准化:11类API覆盖90%业务场景。
多模态支持:图文/视频生成API支持20+文件格式。
跨平台兼容:Kubernetes/OpenStack/国产信创全适配。
🏢行业落地:从实验室到千行百业

1️⃣ 典型应用场景
2️⃣ 开发者实践指南
架构设计:微服务化部署,模块按需扩展。
安全基线:默认开启敏感词过滤,定期更新词库。
性能调优:结合业务流量特征动态分配GPU资源。
持续迭代:建立模型效果-业务指标关联评估体系。
📏标准中的刚性功能与性能要求
标准对中间件的功能、性能、安全等提出了明确的“硬性”要求,确保系统可用性、可扩展性与合规性:
1️⃣ 性能要求
并发能力:应能同时处理100个并发请求,95%请求5秒内响应。
高可用性:系统非故障时间不低于99%。
数据检索:支持10亿级向量数据毫秒级检索,混合索引提升召回率。
2️⃣ 安全性要求
数据加密:传输与存储均需TLS/SSL加密,支持国密算法。
身份认证:多因子认证,账号锁定与自助解锁机制。
权限管理:基于角色的访问控制,字段级数据隔离。
敏感词过滤:多语言支持,动态更新词库,误判率<0.1%。
区块链审计:所有关键操作上链存证,支持司法溯源。
3️⃣ 接口与兼容性
API标准化:所有模块间及对外接口均采用HTTP协议,输入输出格式、参数、返回结果有明确定义。
多模态支持:文本、图像、视频、音频等多种数据格式输入输出。
数据库兼容:支持主流SQL/NoSQL/图数据库,文件接口兼容PDF、Office、WPS、HTML等。
4️⃣ 模型训练与微调
Lora微调:支持Lora/PEFT等高效微调方式,训练精度支持fp16,宜支持bf16、fp32。
数据预处理:自动清洗、标准化、标注,确保数据质量。
强化学习:支持DPO算法,宜支持PPO等。
5️⃣ 监控与评测
实时监控:资源使用、响应时间、错误率等关键指标实时监控。
性能评测:支持MMLU、C-Eval、GSM8K等主流评测,自动生成评估报告。
🔬技术细节:模块协同与API实战解析
1️⃣ 模块间数据流引擎
以“智能客服工单处理”为例,数据流动如下:
用户输入:通过应用接口接收语音投诉。
安全拦截:敏感词过滤、权限校验。
智能体规划:任务拆分(语音转文本→订单号提取→物流查询→生成回复)。
工具调用:ASR模型+CRM系统API+GPT-4生成文本。
数据检索:向量数据库调取相似案例,响应时间<200ms。
模型调度:动态分配GPU资源,保障实时性。
结果反馈:同步更新知识库,优化后续查询。
实测成效:某物流企业工单处理时效从15分钟缩短至90秒,人力成本降低70%。
2️⃣ API接口实战示例
以模型微调为例,标准API设计兼顾灵活性与安全性:
# 启动Lora微调任务
response = requests.post(
url="/inter_gpt/start_finetune",
json={
"finetune_name": "医疗影像诊断模型",
"finetune_model": "qwen-7b",
"finetune_dataset": ["med_data_v1.json"],
"finetune_epochs": 20,
"security_token": "ENC(加密令牌)"
}
)
# 区块链存证自动触发,训练过程关键参数上链
关键设计亮点:
动态量化:支持FP16/BF16混合精度训练,显存占用减少40%。
断点续训:异常中断后可从最近检查点恢复,避免数据重复计算。
合规审计:所有微调操作生成数字指纹,存证于国产区块链。
大模型应用中间件API接口(主要API接口,但不限于下表罗列)
🛡️安全体系:三层防护,理论到落地

1️⃣ 数据安全“铁三角”
2️⃣ 模型安全“防火墙”
输入过滤:正则+AI语义分析混合检测,误判率<0.1%。
输出矫正:对暴力、偏见等内容实时修正。
漏洞扫描:每周自动检测API的OWASP Top 10风险项。
3️⃣ 运维安全“双保险”
区块链存证:关键操作生成Merkle树存证,支持司法取证。
零信任架构:每次API调用需验证设备指纹+动态令牌,防御中间人攻击。
🏆行业深度案例剖析
1️⃣ 电网设备智能巡检
挑战:日均10万+设备告警,传统规则引擎误报率高达35%。
解决方案:用5万条历史工单微调行业模型,F1值从0.62提升至0.89;多模态输入融合红外图像、传感器数据、维修日志,严重故障直连调度系统。
成效:故障识别准确率提升至92%,年度运维成本减少2800万元。
2️⃣ 金融合规审查
挑战:千页级合同需3小时内审查,人工漏检率超15%。
解决方案:上传2000份历史合同至向量数据库,建立条款关联图谱,智能体自动提取关键条款并比对监管规则库。
成效:审查效率提升40倍,风险条款检出率达99.3%。
🛠️开发者指南:避坑与实践
1️⃣ 性能调优“四步法”
资源分配:
实时任务独占GPU,保障低延迟。
批处理任务共享GPU池,提升利用率。
缓存策略:
高频查询结果缓存至Redis,TTL动态调整。
向量检索启用HNSW索引,内存占用减少50%。
异步处理:
耗时操作转为队列任务,HTTP接口秒级响应。
监控看板:
关键指标:GPU利用率/API错误率/知识库命中率。
智能告警:自动触发扩容。
2️⃣ 常见问题排查
🔮未来展望:标准化如何重塑AI生态?
-wsoy.jpg)
1️⃣ 技术演进路线
2024-2025:
智能体自主进化,强化学习自动优化工作流。
边缘中间件,支持10MB级轻量化部署,适应物联网设备。
2026-2030:
跨平台互联,建立模型能力交易市场,实现算力-数据-模型动态调配。
人机共治,智能体可解释性提升,支持人类专家介入修正决策。
2️⃣ 产业影响预测
📝总结
《大模型应用中间件通用技术要求》以九大模块为核心,明确了AI中间件的功能、性能、安全等刚性要求,推动了大模型应用的标准化、模块化、可扩展化。标准不仅解决了企业在集成、训练、安全、运维等方面的痛点,更通过API标准化、多模态支持、区块链审计等创新机制,极大降低了AI落地门槛,加速了AI能力在各行业的规模化应用。未来,随着标准的持续演进与生态的繁荣,AI中间件有望成为“AI原生操作系统”,支撑百万级智能体协同作业,重塑产业智能化格局。
🏅【省心锐评】
“中间件标准是AI时代的‘集装箱革命’——统一了技术接口的乱局,让创新聚焦业务价值而非重复造轮子。未来十年,得标准者得生态话语权。”

评论