.png)
%20%E6%8B%B7%E8%B4%9D-xrkv.jpg)

【摘要】Google DeepMind与耶鲁大学联合推出270亿参数模型C2S-Scale 27B,通过解析单细胞RNA数据,成功识别出可将“冷肿瘤”转化为“热肿瘤”的关键药物,首次实现AI生成生物假设的实验闭环。
引言
在信息技术与生命科学深度交融的今天,我们正见证一个新时代的开启。人工智能,特别是大型语言模型(LLM),已不再局限于理解人类语言。它们开始学习一种更古老、更复杂的语言——细胞的语言。Google DeepMind与耶る大学的最新合作成果,正是这一跨界探索的里程碑。他们联合推出的Cell2Sentence-Scale 27B(C2S-Scale 27B)模型,将AI的认知边界从文本延伸至单细胞转录组的微观世界。
这项研究的核心目标直指现代免疫肿瘤学的一大顽疾——“冷肿瘤”。这类肿瘤巧妙地伪装自己,逃避免疫系统的监视与攻击,导致许多先进的免疫疗法收效甚微。传统药物研发周期漫长,失败率高。而C2S-Scale 27B的出现,则展示了一种全新的科研范式。它不仅能从海量生物数据中高效筛选潜在靶点,更能生成可被实验验证的科学假设。本文将深度剖析该模型的技术架构、其在攻克“冷肿瘤”难题中的关键作用、以及这一“AI假设-实验验证”闭环对未来药物研发和精准医疗的深远影响。
一、 AI与生物学的交汇点 - Cell2Sentence模型的技术解构
%20拷贝-dszh.jpg)
C2S-Scale 27B并非凭空诞生,它的背后是大型语言模型技术在生物信息学领域的精妙适配与深度优化。理解其技术内核,是把握此次突破精髓的第一步。
1.1 基础架构溯源 - 从Gemma到C2S-Scale 27B
C2S-Scale 27B的技术根基,是Google开源的Gemma大型语言模型系列。Gemma本身是为通用自然语言处理任务设计的,其架构借鉴了Gemini模型的成功经验,在性能和效率上取得了良好平衡。选择Gemma作为起点,主要基于以下考量。
强大的序列建模能力。LLM的核心优势在于捕捉序列数据中的长距离依赖关系。基因表达谱同样可以被视为一种序列,其中基因间的相互作用和调控关系,类似于词语间的语法和语义关联。
成熟的Transformer架构。Gemma沿用了Transformer架构,其自注意力机制(Self-Attention)能够有效权衡序列中不同元素的重要性,这对于识别复杂生物通路中的关键基因至关重要。
开源带来的可扩展性。Gemma的开源属性,为研究团队在其基础上进行领域适配和二次开发提供了极大便利,降低了从零构建一个超大规模模型的门槛。
从Gemma到C2S-Scale 27B的演进,是一次领域迁移(Domain Adaptation)的经典实践。研究团队并非简单地将生物数据喂给通用模型,而是进行了深度定制化训练,使其从一个“语言学家”转变为一个“细胞生物学家”。最终形成的270亿参数规模,确保了模型有足够的能力去学习和表征极其复杂的细胞状态和基因调控网络。
1.2 “细胞语言”的解码器 - 单细胞转录组学数据处理
要让AI理解“细胞语言”,首先要定义这种语言的格式。此次研究采用的核心数据是**单细胞RNA测序(scRNA-seq)**数据。这种技术能够测量单个细胞内成千上万个基因的表达水平,为我们提供了前所未有的细胞异质性视图。
然而,scRNA-seq数据也带来了独特的挑战。
高维性(High-dimensionality)。每个细胞的测量维度可达数万个基因,形成一个庞大而稀疏的表达矩阵。
稀疏性(Sparsity)。由于技术限制,许多实际表达的基因在测序中可能未能被捕获,导致数据中存在大量“零值”,这并非代表基因不表达。
噪声与批次效应(Noise and Batch Effects)。实验操作、测序深度等因素会引入技术噪声和系统性偏差,干扰真实的生物信号。
C2S-Scale 27B的核心任务之一,就是克服这些挑战,将原始的基因表达计数矩阵,转化为模型可以理解的、蕴含生物学意义的向量表示(Embeddings)。这个过程可以类比为自然语言处理中的“词嵌入”,只不过这里的“词”是基因,“句子”则代表一个细胞的完整转录状态。模型通过学习,将功能相似或存在调控关系的基因映射到向量空间中相近的位置,从而构建出对细胞状态的深层理解。
1.3 270亿参数的规模效应与能力涌现
在大型模型领域,规模(Scale)往往能带来质变。C2S-Scale 27B的270亿参数并非简单的数字堆砌,而是其强大能力的基础。
模式识别的深度。巨大的参数量意味着模型可以构建更复杂、更深层次的内部表示。它能够捕捉到超越简单线性关系的、非显性的基因协同表达模式(Gene Co-expression Patterns),这些模式往往对应着特定的生物学功能通路或细胞亚型。
抗噪声能力。大规模模型在训练过程中接触了海量数据,使其对数据中的随机噪声具有更强的鲁棒性。它能更好地从稀疏、嘈杂的scRNA-seq数据中提炼出稳定、可复现的生物信号。
零样本/少样本学习潜力。虽然此次研究是针对特定任务进行训练,但大规模预训练赋予了模型一定的泛化能力。未来,它可能在没有见过特定细胞类型或药物扰动的情况下,做出有意义的预测,这便是“能力涌现”(Emergent Abilities)在生物学领域的体现。
1.4 训练范式与目标函数设计
将LLM应用于生物数据,其训练范式也需要相应调整。研究团队可能采用了类似**掩码语言模型(Masked Language Model, MLM)**的自监督学习策略。具体来说,他们可能在训练中随机“遮盖”掉一个细胞表达谱中的某些基因,然后让模型根据剩余基因的表达情况,预测被遮盖基因的表达水平。
通过这种方式,模型被迫学习基因与基因之间的内在关联。
如果两个基因经常协同上调或下调,模型就会学会它们之间的正相关关系。
如果一个基因是转录因子,能调控一系列下游基因,模型就会学到这种层级化的调控结构。
经过海量单细胞数据的反复训练,C2S-Scale 27B的内部参数便编码了大量关于基因功能、调控网络和细胞状态转换的先验知识。这为后续执行药物筛选等下游任务,奠定了坚实的生物学知识基础。
二、 攻坚免疫肿瘤学 - “冷肿瘤”的转化难题
理解了模型的技术底座,我们再来看它要解决的具体科学问题——如何点燃“冷肿瘤”。这是当前癌症免疫治疗领域最棘手的挑战之一。
2.1 “冷肿瘤”与“热肿瘤”的免疫学分野
肿瘤根据其与免疫系统的互动状态,可以粗略地分为“热肿瘤”和“冷肿瘤”。二者的核心区别在于肿瘤微环境(Tumor Microenvironment, TME)中免疫细胞的浸润程度和活性状态。
简单来说,“热肿瘤”是免疫系统已经识别并试图攻击,但被肿瘤抑制了的战场。而**“冷肿瘤”则是免疫系统根本没有发现,或者无法进入的“法外之地”**。
2.2 现有免疫疗法的瓶颈
以PD-1/PD-L1抑制剂为代表的免疫检查点抑制剂(ICIs)是近年来癌症治疗的革命性突破。其作用原理是“松开刹车”,重新激活那些已经进入肿瘤但被“耗竭”的T细胞。
这个机制决定了ICIs的生效前提是:肿瘤微环境中必须存在足够数量的、可被重新激活的T细胞。这恰恰是“冷肿瘤”所缺乏的。因此,全球约有70-85%的实体瘤患者无法从ICIs治疗中获益,其根本原因大多与“冷肿瘤”表型相关。
2.3 “冷转热”策略的理论基础与挑战
将“冷肿瘤”转化为“热肿瘤”,即“冷转热”(Cold-to-Hot Transition),已成为全球免疫联合疗法的研究共识和核心策略。其目标是人为地创造一个有利于免疫细胞浸润和杀伤的肿瘤微环境。
目前主流的“冷转热”策略包括:
肿瘤疫苗。通过递送肿瘤特异性抗原,在体外激活T细胞,再输回体内,或直接在体内诱导免疫反应。
放疗/化疗。通过诱导肿瘤细胞免疫原性死亡(Immunogenic Cell Death, ICD),释放肿瘤抗原和“危险信号”,吸引免疫细胞。
溶瘤病毒。病毒在感染并裂解肿瘤细胞的同时,会引发强烈的局部炎症反应,招募免疫细胞。
靶向药物。针对抑制免疫反应的关键信号通路(如Wnt/β-catenin通路)进行干预。
尽管策略众多,但挑战依然巨大。首先,肿瘤的免疫逃逸机制极其复杂且异质性高,单一策略往往难以奏效。其次,如何精准筛选出对特定“冷转热”策略敏感的患者群体,是实现个体化治疗的关键。最后,联合用药的毒副作用和复杂的相互作用,也给临床应用带来了困难。
正是在这个背景下,利用AI从海量数据中寻找新的、更高效的“冷转热”药物靶点,成为了一个极具吸引力的研究方向。
三、 AI驱动的药物发现 - 从虚拟筛选到实验验证
%20拷贝-ocds.jpg)
C2S-Scale 27B在此次研究中扮演的核心角色,是一个高效的“假设生成器”和“药物筛选器”。它完美展示了AI如何将复杂的生物数据转化为可执行的实验方案。
3.1 假设生成 - AI的洞察力引擎
传统药物发现往往依赖于已知的生物学通路,研究人员基于现有知识提出假设,然后进行实验验证。这个过程受限于人类知识的边界。
C2S-Scale 27B则采用了一种数据驱动的方式。它不依赖于预设的通路图,而是直接从单细胞数据中学习基因间的相互作用模式。当模型被问及“在低剂量干扰素信号(一种模拟免疫激活的微弱信号)存在时,哪种药物能够最大程度地增强肿瘤细胞的抗原呈递通路?”时,它实际上在执行一个复杂的推理任务。
模型会遍历其内部学到的庞大基因调控网络,模拟数千种药物对细胞转录组的扰动效应,并评估哪种扰动最符合“增强抗原呈递”这一目标状态。这个过程超越了简单的模式匹配,是一种基于深度生物学理解的因果推断。最终,模型生成的不是一个简单的药物列表,而是一个附带作用机制解释的、排序最高的科学假设。
3.2 虚拟药物筛选流程
整个由AI驱动的虚拟药物筛选过程,可以被抽象为以下几个步骤,这构成了一个高效的“干实验”(in silico)流程。
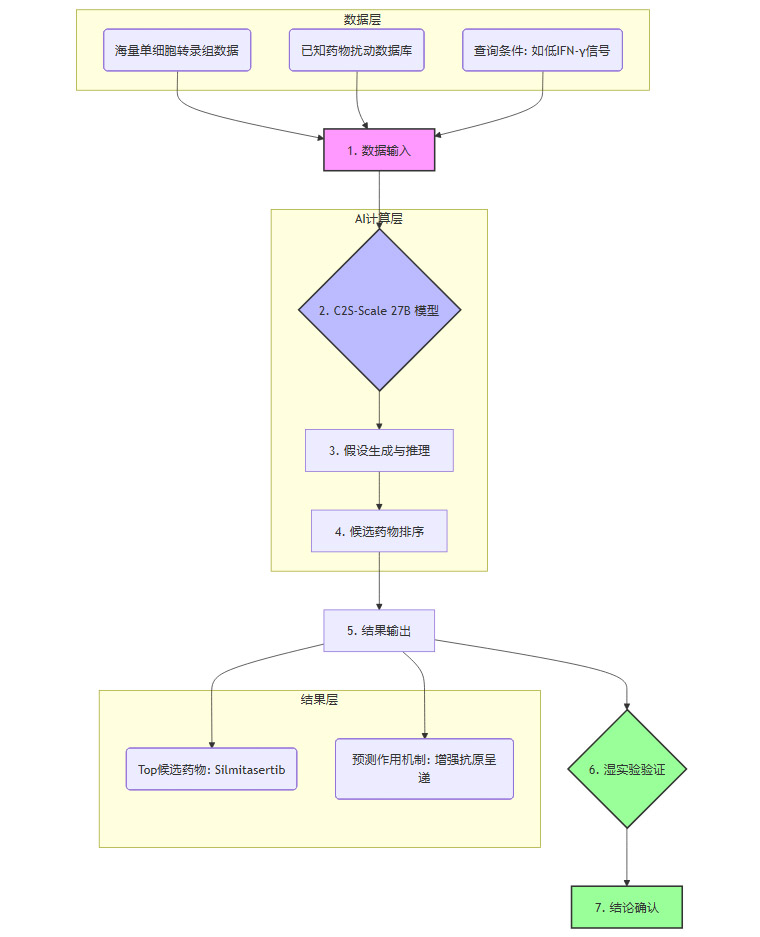
这个流程的核心优势在于其速度和规模。研究团队利用该模型对超过4000种药物进行了虚拟筛选,这种规模的实验如果通过传统的细胞实验来完成,将耗费巨大的时间和资源。AI在这里扮演了“导航员”的角色,从数千种可能性中精准定位出最有希望的航向。
3.3 关键发现 - Silmitasertib (CX-4945) 的作用机制
在4000多种候选药物中,C2S-Scale 27B模型给出的最优解是Silmitasertib(CX-4945)。这是一种**酪蛋白激酶2(CK2)**的抑制剂。CK2是一种广泛存在且高度活跃的丝氨酸/苏氨酸蛋白激酶,参与细胞增殖、凋亡、DNA修复等多种关键生物学过程,在多种癌症中都表现出异常高活。
模型的预测直指一个关键机制:在特定的免疫信号背景(即低剂量干扰素刺激)下,抑制CK2能够显著增强肿瘤细胞的抗原呈递能力。抗原呈递是免疫系统识别肿瘤细胞的“身份证查验”环节。肿瘤细胞通过其表面的主要组织相容性复合体I类分子(MHC-I),将内部的蛋白质片段(抗原)展示给T细胞。如果这个过程受阻,肿瘤细胞就相当于摘掉了“身份证”,T细胞无法识别。
Silmitasertib的作用,正是在免疫系统试图“查验身份证”(低剂量干扰素信号)时,强制肿瘤细胞更清晰、更大量地展示其内部的异常抗原。这相当于把一个伪装起来的敌人,重新暴露在免疫系统的火力之下,从而实现了“冷转热”的关键一步。
3.4 从“干实验”到“湿实验” - 闭环验证的里程碑
一项AI预测的价值,最终取决于它是否能被真实世界的实验所证实。这也是此次研究最具里程碑意义的部分。研究团队在AI给出预测后,迅速转向了**“湿实验”(wet-lab experiments)**进行验证。
他们在体外培养的癌细胞系中,模拟了模型预测的条件(即使用低剂量干扰素和Silmitasertib联合处理),然后通过流式细胞术等技术,检测细胞表面MHC-I分子的表达水平。实验结果与AI的预测高度一致,证实了Silmitasertib确实能够在特定条件下,显著上调肿瘤细胞的抗原呈递。
这个**“数据-AI假设-实验验证”**的完整闭环,是AI驱动生物学研究走向成熟的重要标志。它证明了大规模AI模型不仅是强大的数据分析工具,更是能够启发和指导科学发现的“灵感引擎”。这一范式极大地缩短了从海量数据到有效生物学洞见的周期,为药物研发领域带来了革命性的方法论。
四、 范式革命 - AI驱动生物学发现的新纪元
Google DeepMind与耶鲁大学的这项合作,其意义远超发现一种潜在药物。它真正撼动的是生物医学研究的底层逻辑,预示着一个由AI驱动的科学发现新范式的到来。
4.1 科研范式的重塑 - 从“知识驱动”到“数据驱动”
传统的生物医学研究,本质上是**“知识驱动”或“假设驱动”**的。研究人员基于已有的生物学理论和文献,提出一个科学假设,然后设计实验去验证或推翻它。这个过程严谨,但也存在明显的局限性。
认知边界。人类的知识和想象力是有限的,我们很难跳出已有的理论框架去思考全新的、反直觉的生物学机制。
效率低下。从提出假设到获得初步验证,往往需要数月甚至数年的时间,试错成本极高。
数据利用不充分。面对基因组学、转录组学等技术产生的海量数据(Big Data),传统分析方法常常力不从心,大量有价值的信息被淹没在噪声中。
C2S-Scale 27B所代表的,则是一种**“数据驱动”**的新范式。它将起点从人类的先验知识,转移到了数据本身。模型通过无监督或自监督的方式,从数据中自主学习规律,并生成全新的、人类未曾预想过的假设。
两种科研范式的核心区别
这次研究构建的**“数据-AI假设-实验验证”闭环**,是这一新范式走向成熟的关键一步。它证明了AI不仅能“看懂”数据,更能“思考”数据,提出具有高度可信度和可操作性的科学问题。这标志着AI在科研领域的角色,正从一个辅助分析的工具,转变为一个能够启发创新的伙伴。
4.2 加速药物研发 - 缩短周期与降低成本
新药研发是一场旷日持久且耗资巨大的豪赌。一款新药从最初的靶点发现到最终上市,平均需要10-15年时间,耗资超过20亿美元,且失败率高达90%以上。其中,早期靶点发现和候选化合物筛选阶段,是时间和资源消耗的重灾区。
AI的介入,有望从根本上改变这一局面。
前端提速。C2S-Scale 27B在数千种药物中进行虚拟筛选,其效率是传统高通量筛选(HTS)无法比拟的。它将原本需要数年才能完成的靶点探索工作,压缩到了数周甚至数天。
后端增效。通过提供更精准、机制更明确的候选药物,AI大大提高了后续临床前和临床试验的成功率。它帮助研究人员**“快速失败,廉价失败”(Fail Fast, Fail Cheap)**,尽早淘汰掉那些没有潜力的候选者,将宝贵的资源集中在最有希望的项目上。
我们可以用一个简化的流程图来展示AI对药物研发流程的优化。
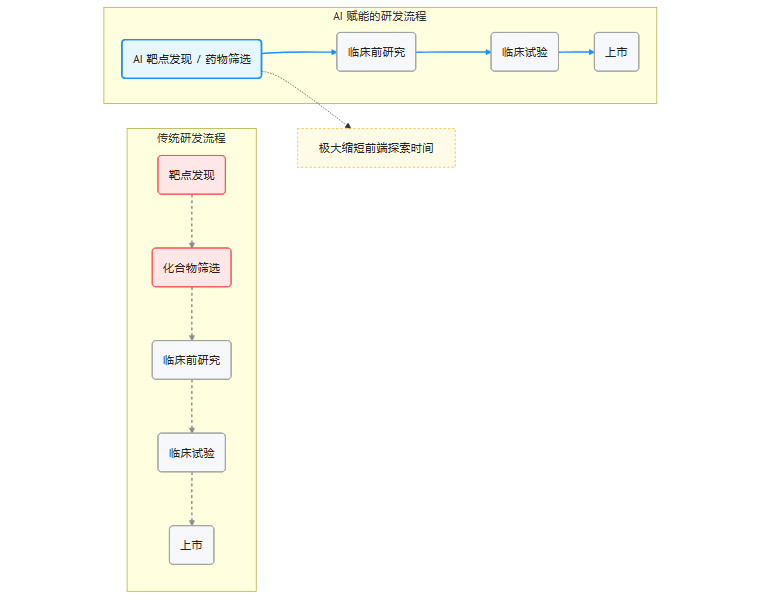
AI通过整合靶点发现和化合物筛选步骤,直接输出了一个高潜力的“药物-靶点-机制”组合,从而绕过了传统流程中最耗时、最不确定的环节。
4.3 开放科学的催化剂 - 开源模型与社区协作
Google DeepMind和耶鲁大学选择将C2S-Scale 27B模型及相关工具在Hugging Face和GitHub等平台公开发布,这一举动本身就具有深远意义。它体现了科技巨头与顶尖学术机构对“开放科学”理念的拥抱。
可复现性与透明度。任何研究者都可以下载模型和代码,复现此次研究的结果。这增强了研究结论的可靠性,是科学精神的核心要求。
加速全球创新。全球的生物信息学家、癌症研究者和AI工程师,都可以在此基础上进行二次开发。他们可以:
将模型应用于其他疾病领域,如自身免疫病或神经退行性疾病。
尝试用新的数据集对模型进行微调,以解决更具体的生物学问题。
改进模型架构或训练方法,开发出性能更强的下一代生物学基础模型。
构建生态系统。开源能够吸引全球的智慧,围绕一个核心技术形成一个活跃的开发者和研究者社区。这种社区驱动的创新模式,其速度和广度是任何单一机构都无法比拟的。
此举不仅分享了一项技术成果,更是在播撒创新的种子,有望催生出一个围绕大规模AI模型进行生物医学研究的新生态。
五、 从代码到临床 - 未来之路与挑战
%20拷贝.jpg)
一项突破性的基础研究成果,要真正转化为能够惠及患者的疗法,还有很长的路要走。Silmitasertib的发现只是一个起点,后续的临床转化路径清晰而充满挑战。
5.1 Silmitasertib的下一步 - 从实验室到临床前研究
在进入人体临床试验之前,Silmitasertib作为“冷转热”诱导剂的潜力,还需要在一系列更复杂的临床前研究中得到系统性验证。
5.1.1 适应性与普适性验证
当前的研究主要在体外细胞系中得到了验证。下一步的关键是回答:这种效应是否具有普适性?
跨肿瘤类型验证。需要在多种来源的“冷肿瘤”细胞系中进行测试,例如胰腺癌、胶质母细胞瘤、前列腺癌等,以确定Silmitasertib的适用范围。
不同免疫环境下的表现。肿瘤微环境极其复杂,除了干扰素信号,还存在TGF-β、IL-10等多种免疫抑制性细胞因子。需要研究在这些复杂信号的干扰下,Silmitasertib是否依然有效。
5.1.2 体内模型(In Vivo)的功能性验证
细胞实验的成功,不代表在活体动物中同样有效。体内动物模型是连接基础研究与临床应用不可或缺的桥梁。
人源肿瘤异种移植(PDX)模型。将患者的肿瘤组织直接移植到免疫缺陷小鼠体内,这种模型能最大程度地保留原始肿瘤的异质性和微环境特征。在PDX模型中验证Silmitasertib的“冷转热”效果,将是其临床转化潜力的重要证据。
免疫健全小鼠模型。在具有完整免疫系统的小鼠模型中,才能真正评估“冷转热”后,是否能有效激活T细胞并引发肿瘤消退。这是检验整个免疫杀伤链条是否通畅的关键。
5.1.3 安全性与毒理学评估
任何药物进入临床前,都必须经过严格的安全性评估。虽然Silmitasertib作为CK2抑制剂已经有了一些临床研究数据,但其作为免疫调节剂的长期、联合用药的安全性,仍需重新进行系统性的毒理学研究。
5.2 联合疗法的协同效应 - 1+1>2的潜力
Silmitasertib的定位并非单打独斗的“杀手”,而是一个**“增敏剂”或“协同伙伴”**。其最大的价值在于,为那些原本无效的免疫疗法创造生效的条件。因此,探索其与现有免疫疗法的联合应用,是未来的核心方向。
联合免疫检查点抑制剂(ICIs)。这是最符合逻辑的组合。Silmitasertib负责将T细胞“招募”进肿瘤,并将肿瘤“点亮”,而PD-1/PD-L1抑制剂则负责为这些进入战场的T细胞“松绑”,使其恢复杀伤功能。二者在作用机制上完美互补,有望在“冷肿瘤”患者中实现“1+1>2”的疗效。
联合肿瘤疫苗或CAR-T疗法。对于肿瘤疫苗或CAR-T这类旨在引入或增强肿瘤特异性T细胞的疗法,Silmitasertib同样能发挥关键作用。它通过上调MHC-I,确保肿瘤细胞能被这些“精确制导”的T细胞高效识别和清除。
联合疗法协同作用示意图
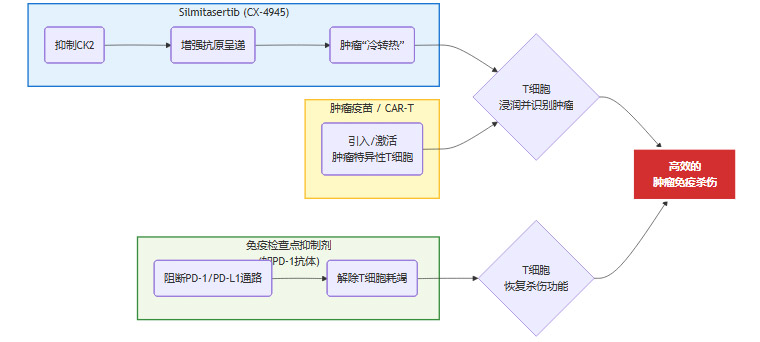
这个示意图清晰地展示了Silmitasertib如何作为核心枢纽,为多种先进的免疫疗法赋能。
5.3 迈向个体化医疗 - AI驱动的患者分层
并非所有“冷肿瘤”患者都能从Silmitasertib联合疗法中获益。如何精准地筛选出最有可能应答的患者群体,即患者分层(Patient Stratification),是决定该疗法临床成败的关键。
AI在此同样能扮演重要角色。C2S-Scale 27B或其衍生模型,未来有望发展成为一种伴随诊断工具。
获取患者肿瘤样本。通过活检获取少量肿瘤组织,并进行单细胞RNA测序。
AI模型分析。将患者的单细胞转录组数据输入AI模型。
预测疗效。模型根据肿瘤细胞的基因表达特征,特别是CK2通路和抗原呈递通路的基线状态,预测该患者对Silmitasertib联合疗法的敏感性。
制定个体化治疗方案。基于模型的预测结果,医生可以为患者制定更具针对性的联合治疗方案,从而最大化疗效,最小化无效治疗带来的毒副作用和经济负担。
这种基于AI的生物标志物(Biomarker)发现和应用,将是实现真正个体化免疫治疗的终极目标。它让治疗决策从基于群体的统计概率,转向了基于个体生物学特征的精准预测。
结论
Google DeepMind与耶鲁大学的合作,为我们清晰地描绘了AI技术如何深度赋能生命科学研究的未来图景。C2S-Scale 27B模型的成功,其核心价值不在于发现了一种名为Silmitasertib的潜在药物,而在于它成功走通了一条从海量非结构化生物数据,到可被实验验证的、全新的科学假设的完整路径。
这一成就标志着AI在科研领域角色的根本性转变。它不再仅仅是处理和分析数据的工具,而是成为了能够提出深刻洞见、启发创新方向的“智慧伙伴”。这种“数据驱动”的科研新范式,通过“AI假设-实验验证”的快速迭代闭环,正在重塑药物发现的传统流程,有望显著缩短研发周期、降低失败风险。
从代码到疗法,这条路依然漫长且充满挑战。Silmitasertib的临床转化需要严谨的科学验证,而AI模型的泛化能力、可解释性以及在更复杂生物系统中的应用,也需要持续的技术攻坚。但方向已经明确,AI与生物医学的融合已不再是远景展望,而是正在发生的现实。我们正站在一个新时代的入口,一个由算法和算力驱动,旨在更深刻地理解生命、更精准地战胜疾病的时代。
📢💻 【省心锐评】
AI正从数据分析师进化为科学假说引擎。它重塑了从海量数据到可验证洞见的科研路径,将生物医学发现的起点前移。

评论