.png)


【摘要】AI 真正进入 ERP,从来不是把一个大模型接口接到老系统前面,再做一个会说话的页面。企业一旦希望 AI 不只会问答,还能理解业务、解释口径、调用流程、生成草稿,甚至在受控边界内参与执行,就必须面对一整套架构问题。数据从哪里来,语义如何统一,模型怎样分工,知识如何沉淀,查询如何追溯,Agent 如何安全调用 API,权限和审计如何兜底,这些问题一个都绕不过去。真正成熟的 AI+ERP 架构,核心不是“模型有多强”,而是数据可理解、知识可检索、动作可调用、过程可治理。这意味着企业要从“ERP+一个模型”的想法,转向“ERP 数据底座 + 多模型能力 + 企业知识库 + 受控 API + 治理中枢”的体系化设计。平台化的 AI 中台,不是锦上添花的附属层,而是让智能能力稳定落地、持续复用、统一治理的关键。
引言
企业一旦认真推进 AI+ERP,技术团队最先遇到的麻烦,往往不是模型效果,而是架构问题。
前两篇文章已经把趋势和风险说得比较清楚。ERP 一定会被 AI 重构,这个方向没有太大悬念。问题在于,很多企业一谈到 AI+ERP,还是下意识地把它理解成一个前端项目。好像只要在 ERP 外面接上大模型,再做一个问答框,就算完成了智能升级。这个判断放在演示阶段也许还能成立,一旦进入真实业务,它很快就会失效。
原因并不复杂。ERP 不是普通信息系统,它承载的是企业最核心的经营事实。客户、供应商、订单、库存、采购、生产、财务、审批、收付款,这些对象都在里面。AI 如果真的要进入 ERP,就不只是“会回答几个问题”,而是要理解这些对象之间的关系,知道指标口径,知道流程边界,知道权限范围,还要在必要时通过安全接口去发起流程、生成草稿、回写结果。到了这个阶段,技术问题已经不再是“模型能不能生成一句话”,而是整套架构能不能支撑一个可用、可控、可审计的智能系统。
所以,讨论 AI+ERP 技术架构,不能只停留在“选哪家大模型”或者“要不要上 RAG”。企业真正要设计的是一张完整的架构图。底层要有稳定的数据层,中间要有清晰的语义层和模型层,知识库要能补足上下文,RAG 和查询层要能区分知识问答与事实问答,Agent 和 API 层要能受控执行,再往上还要有权限、安全、日志、审计和 AI 中台做统一治理。
换句话说,AI 真正进入 ERP,靠的不是一个模型,而是一整套技术体系。
这篇文章要解决的,就是这个问题。企业如果希望 AI 真正进入 ERP,而不是停留在演示层,技术架构到底应该怎么设计。
🧭 一、架构总览与核心原则
%20拷贝.jpg)
1.1 AI+ERP 不是单层能力,而是分层架构
企业如果想把 AI 放进 ERP,最忌讳的做法就是“见缝插针”。财务团队自己接一个报表助手,采购团队自己接一个供应商评分模型,IT 团队再单独做一套问答系统,最后系统里到处都是“智能功能”,但彼此之间没有统一的数据口径,也没有统一的权限控制,更没有统一的 API 与日志体系。这样的结果通常不是得到一个智能 ERP,而是得到一堆新的孤岛能力。
更稳妥的方式,是从一开始就采用分层架构。这个架构不只是为了让图画得更漂亮,而是为了把 AI+ERP 这件事拆成几个可以治理、可以扩展、可以替换的能力层。
建议采用七层架构:
ERP 数据层
数据治理与语义层
AI 模型层
企业知识库层
RAG 与智能查询层
Agent 与 API 执行层
安全治理层
如果企业规模较大、系统复杂度较高,这七层之上还需要一个统一能力层,也就是 AI 中台 / 智能中枢,承担模型管理、Agent 编排、知识库治理、权限控制和监控评估等职责。
1.2 七层结构解决的是七类不同问题
这七层不是简单罗列,它们各自承担不同任务。
这一结构背后的核心原则可以浓缩成一句话。数据能取到,模型能判断,知识能补上下文,API 能安全执行,过程必须可治理。
1.3 架构设计的重点,不是堆技术,而是控制边界
企业常见一个误区,认为 AI 架构就是把大模型、向量库、RAG、Agent、API 网关这些词串起来。真正成熟的架构,重点不在技术词汇本身,而在边界控制。什么数据可以进模型,什么知识可以被检索,什么查询可以走 SQL,什么动作只能走 API,什么 Agent 可以发起流程,什么输出必须人工复核,这些边界决定了 AI+ERP 能不能进入生产环境。
如果用一句更直接的话来概括,就是 AI+ERP 的架构设计,本质上是在回答“谁能看到什么、谁能理解什么、谁能调用什么、谁能改变什么”。
🗂️ 二、ERP 数据层,AI 的事实基础
2.1 主数据是架构锚点,不是普通基础表
ERP 的数据层首先是主数据。客户、供应商、物料、员工、组织、会计科目、仓库、BOM,这些对象不是普通静态信息,它们是整个 ERP 业务网络的锚点。AI 能不能在 ERP 中理解“谁是谁、什么是什么、这条单据属于哪个对象”,都取决于主数据质量。
主数据问题在 ERP 里很常见。一个客户多个名称,一个物料多个编码,一个供应商在采购和财务模块中是不同叫法,组织调整后旧编码仍在沿用。这类问题在传统 ERP 中通常靠人补足理解,业务还能勉强跑下去。到了 AI 场景,这种模糊会立刻放大。主数据不一致,AI 的理解就不可能稳定。
2.2 交易数据决定 AI 是否能做判断
交易数据是 ERP 最核心的事实来源。销售订单、采购订单、出入库记录、生产报工、发票、凭证、应收应付、收付款记录,这些数据不是“辅助信息”,而是 AI 做预测、推荐、异常检测的主要输入。
这一层的关键不只是有没有数据,而是数据是否可持续使用。订单状态有没有版本变化,库存是否有冻结和在途区分,收付款是否有准确匹配关系,发票与合同是否可关联,这些都会直接影响模型质量。
2.3 流程数据决定 AI 是否能理解过程
很多企业做数据治理时,只关注主数据和交易数据,忽视流程数据。实际上,流程数据对 AI+ERP 非常关键。审批记录、流程节点、操作日志、角色分配、任务流转,这些内容决定了 AI 能不能理解业务是怎么被执行的,而不是只看到最后结果。
如果没有流程数据,AI 只能看到订单已完成、审批已通过、库存已变化,但看不到过程中哪里发生了异常、例外如何处理、审批为什么被驳回。这样一来,AI 就很难做归因分析、流程优化和 Agent 级任务编排。
2.4 外部数据补足经营上下文
ERP 虽然是核心系统,但它不是企业全部现实。市场价格、供应商履约状态、客户行为、IoT/MES 现场数据、物流节点状态、行业政策变化,这些信息很多并不原生存在于 ERP 中,但它们会直接影响经营判断。
因此,完整的数据层不应只理解为 ERP 数据库,而应理解为 ERP 主干数据 + 外部上下文数据 的组合。前者提供事实,后者提供环境。缺少前者,AI 没有基础。缺少后者,AI 的判断就会缺乏现实感。
2.5 数据层的工程重点,是治理而不是堆积
数据层建设不是把数据都拉进来就结束了。真正重要的是治理。去重、标准化、口径统一、ETL、实时同步、事件流、历史版本管理、异常值清洗,这些工作看起来不“智能”,却决定了 AI 能不能可信地使用 ERP 数据。
可以用下面这张表总结数据层结构。
数据层不是 AI 的附属输入,而是 AI 在 ERP 中立足的事实基础。
🧩 三、数据治理与语义层,让 AI 看懂 ERP 数据
%20拷贝.jpg)
3.1 有数据不等于 AI 看得懂数据
企业经常说“ERP 里什么数据都有”,这句话只说对了一半。数据存在,不代表 AI 就能理解。ERP 里的字段名、状态值、指标计算方式、业务对象关系,很多都带有强烈的企业语义。AI 若没有语义层支撑,就很容易在“看得见数据”和“理解对数据”之间掉链子。
举一个最常见的例子。销售额到底按订单口径算,还是按发货口径算,还是按开票口径算,还是按回款口径算。传统 ERP 用户可能知道不同报表各自代表什么,AI 如果没有语义层,就很可能把这些概念混在一起。
数据治理与语义层的任务,就是把“系统能存的数据”翻译成“AI 能理解的数据”。
3.2 数据字典不是文档附件,而是 AI 的翻译器
数据字典要做的第一件事,是明确字段解释、指标定义和业务语义。这个层面不是可有可无的“补充资料”,而是 AI+ERP 架构中的核心基础设施。没有数据字典,AI 就只能依赖猜测或者历史上下文理解字段含义,这在 ERP 场景里是不可接受的。
成熟的数据字典至少应包含这些内容:
字段含义
单位与取值范围
所属模块
数据更新时间
是否敏感字段
是否参与关键指标计算
3.3 指标口径库决定 AI 回答是否可信
如果数据字典是词汇表,那么指标口径库就是语义规则库。销售额、库存、利润、采购金额、应收、现金流,这些指标在企业里都有多种可能定义。口径不统一,AI 的回答就会失去可信度。
例如一个很常见的情况,同样是“库存”,业务口径要看是否包含在途、冻结、质检库存,财务口径又可能关注账面库存。AI 如果不能明确自己采用的是哪一种口径,回答很快就会引发争议。
因此,语义层里必须有一套可被程序调用的指标口径库,而不是只放在 Excel 或口头规范中。AI 问答与分析系统能不能被业务接受,很多时候不取决于模型,而取决于口径库是否稳定。
3.4 权限标签和语义模型,要同时存在
ERP 数据不是统一开放资源。不同角色能看到的客户、价格、成本、财务信息都不同。语义层不能只解决“是什么意思”,还必须解决“谁能看什么”。这就要求在指标、字段、对象上打上权限标签,与角色体系联动。
更进一步,还要建立业务语义模型。它描述的不是单个字段,而是指标之间如何计算,对象之间如何关联,场景中应该如何解释。只有这样,AI 才能把 ERP 数据转化为业务含义,而不是停留在数据库字段层面。
🤖 四、AI 模型层,不是一个模型解决所有问题
4.1 AI+ERP 需要的是多模型协同,不是单一大模型
很多企业一谈到 AI+ERP,就直接把问题收敛到“选哪个大模型”。这是一种典型的架构误区。ERP 场景中的问题类型非常复杂,有些是结构化预测,有些是语言理解,有些是最优求解,有些是异常检测,还有些是票据识别。单一模型不可能在所有问题上都最合适。
所以,模型层的正确理解方式,不是“找一个最强模型”,而是为不同业务问题匹配不同模型类型,再通过统一编排层把它们组合起来。
4.2 机器学习模型适合结构化预测
机器学习模型最适合处理结构化数据上的预测与评分任务。销售预测、库存优化、客户流失预测、供应商评分、采购价格预测,这些都更适合用传统机器学习或时间序列模型处理。
在工程实现上,ARIMA、XGBoost、LightGBM 这类方法都很常见。它们未必像大模型那样“智能感”强,但在 ERP 这类结构化数据场景里,往往更稳、更易解释。
4.3 大模型适合语言理解与生成
大模型的价值主要体现在语言层。自然语言问答、报表摘要、制度问答、合同抽取、经营分析解释、多步骤任务拆解,这些更适合交给 LLM 处理。Llama、ChatGLM 等本地化部署模型,或者企业可控接入的通用大模型,都可以纳入这一层。
但要强调一点,大模型在 ERP 里更像“解释器”和“编排器”,而不是万能判断引擎”。
4.4 优化算法和异常检测是经常被忽视的两类核心能力
ERP 场景里有大量问题不是“预测未来”,而是“求当前最优”。排产优化、补货策略、物流路径、动态定价,都更适合用优化算法来解决。线性规划、遗传算法、组合优化这类方法在生产和供应链中非常常见。
异常检测也是一类很关键的能力。财务欺诈、设备故障、质量异常、库存异常波动,这些往往不是靠问答完成的,而是靠孤立森林、One-Class SVM、自编码器这类模型完成预警。
4.5 OCR 与文档模型是流程智能化的基础能力
发票识别、合同抽取、单据录入、报销票据处理,这些场景并不需要一个能写长文的大模型,而需要 OCR 与文档理解模型。它们在 AI+ERP 架构中的价值非常实际,因为很多业务流程的第一步,就是把非结构化文档转成结构化输入。
可以用下面这张表总结模型层分工。
多模型协同,才是 ERP 场景中真正可落地的 AI。
📚 五、企业知识库层,让 AI 理解企业规则
%20拷贝.jpg)
5.1 ERP 里最难的不是数据,而是规则
ERP 中很多关键知识并不在结构化表里,而在制度、流程文档、合同模板、操作手册和财务政策里。AI 如果只读 ERP 数据,不读这些企业规则,就只能“知道发生了什么”,却不知道“该怎么判断、按什么规则判断”。
比如 AI 判断一笔费用是否违规,不能只看报销单据金额,还要看企业差旅标准、审批权限、报销制度和岗位级别。合同条款是否异常,也不能只读合同文本,还要对照企业标准模板和法务规则。
企业知识库的意义,是让 AI 理解企业,而不是只理解语言。
5.2 知识库应当纳入哪些内容
知识库至少应覆盖以下几类信息:
财务制度
采购政策
报销标准
审批规则
合同模板
产品规格
工艺要求
法务条款
操作手册
常见问题与内部规范
知识库的边界不应只理解为“文档仓库”,而应该理解为企业规则的可检索知识资产。
5.3 知识库不是堆文档,而是持续治理
很多企业做知识库时最容易踩的坑,是把文档统一上传之后就认为工作完成了。真正有用的知识库,必须经过文档清洗、分段、元数据标注、权限控制、版本管理、来源引用、过期规则处理,并明确知识责任人与审批发布流程。
如果没有这些治理动作,知识库会很快变成一堆“看起来都在、实际上没人敢信”的旧材料。AI 一旦从中过时规则中检索内容,后果并不比模型幻觉小。
5.4 工程实现需要向量化与权限协同
知识库的技术实现通常会涉及 Embedding、向量数据库和语义检索。Milvus、Chroma 等向量数据库都可作为底层设施。但对 ERP 场景来说,关键不在选哪家向量库,而在于知识库是否和权限体系打通,是否能保留来源引用,是否能做版本控制。
知识库不是为了让 AI 回答更多,而是为了让 AI 回答得更像企业自己。
🔍 六、RAG 与智能查询层,区分知识问答与事实问答
6.1 企业最容易混淆的,是“知道规则”和“知道事实”
RAG 很热,大模型问答也很热,所以很多企业在设计 AI+ERP 时,第一反应是“把 ERP 文档和报表都扔进知识库,让模型统一回答”。这个想法看起来省事,实际会带来很大问题。因为 ERP 场景中的问题至少有两类,一类是知识问题,另一类是事实问题。
“报销标准是什么”“采购审批金额门槛是多少”“某类合同的违约责任怎么定义”,这类问题本质上是知识检索问题。它们适合走知识库检索和 RAG 路径。
“本月销售额是多少”“这张采购单现在在哪个节点”“A 物料下周可用库存够不够”,这类问题本质上是事实查询问题。它们不能只靠文档检索,而必须走 ERP 数据查询链路。
知识问题查规则,事实问题查数据。 这是 RAG 与 ERP 查询层设计时必须先分清的第一件事。
6.2 RAG 适合补上下文,不适合代替 ERP 查询
RAG 的真正价值,是把企业知识库中的制度、流程、规则、条款拿出来作为上下文增强,帮助模型在回答时更贴近企业语境。它擅长回答“按我们公司的规则,该怎么理解这件事”。但它并不适合直接代替 ERP 查询。
ERP 数据查询有几个强约束。第一,要有准确的时间范围。第二,要有明确的数据口径。第三,要受权限控制。第四,要能追溯来源。RAG 如果被拿来直接“猜事实”,很容易出现两类问题。要么回答看起来很完整,其实依据是过期文档。要么把报表文字描述当成实时事实,结果与 ERP 当前数据不一致。
所以,这一层的设计原则不是“统一都交给大模型”,而是把 RAG 放在它最擅长的位置上,让它负责补足规则和上下文,而不是代替结构化查询引擎。
6.3 正确架构应该是双轨问答
成熟的 AI+ERP 查询层,通常应当采用双轨设计。一条是知识问答链路,一条是数据问答链路。前者走 RAG,后者走 SQL、语义查询层或 ERP API。
可以用这张表来说明双轨结构。
混合问答其实很典型。比如一张报销单是否合规,不能只看制度,也不能只看单据本身。它需要同时读取报销制度、岗位标准、审批规则,再叠加该员工当前单据的金额、项目、出差天数和已报销情况。这种场景就要求 RAG 与 ERP 查询层在同一条链路中协同工作。
6.4 结果必须可追溯,不能只给答案不给依据
RAG 与智能查询层还有一个非常关键的要求,就是可追溯。ERP 场景是强事实场景,AI 给出的答案不能只是“看起来合理”,而必须说明依据来自哪张报表、哪条规则、哪个数据源、哪个时间点。
这一点尤其重要。因为企业真正担心的从来不是 AI 回答慢,而是 AI 回答错了以后无法解释。可追溯架构的价值,就在于让每一个答案都可以追到来源。知识回答要标明依据文档和版本。数据回答要标明指标口径、查询时间和数据源。混合回答则要同时引用两边依据。
可以把这一层理解为 AI+ERP 架构中的“证据层”。它不只是负责把答案生成出来,更负责把答案背后的证据组织出来。
🔌 七、Agent 与 API 执行层,从建议走向受控动作
%20拷贝.jpg)
7.1 AI 真要做事,就必须通过 API,而不是直接碰库
AI 在 ERP 中真正有价值的时刻,往往不是它回答了一个问题,而是它开始参与动作。比如生成采购申请草稿、发起审批、推送异常、写回状态、生成调拨建议、触发提醒、更新流程节点。到了这一步,架构的关键就从“能不能问答”转向“能不能安全做事”。
这里的核心原则必须明确。Agent 要进入 ERP,只能通过 API 或业务服务层,不能直接写生产库。 这是安全问题,也是语义问题。数据库里看到的是表和字段,业务服务层看到的是对象、规则和流程。绕开业务层直接碰库,不只是有风险,更容易破坏状态一致性、跳过校验逻辑和权限链路。
7.2 Agent 的能力需要分级,而不是一次放开
Agent 能做什么,不能靠想象力决定,必须靠分级治理决定。建议把 Agent 能力分成至少四级。
如果企业还要继续往上走,进入闭环自动执行,那通常已经不是一个通用级别,而应限定在少数低风险白名单场景中。
Agent 的能力分级,本质上是为了回答一个问题,AI 到底能够改变哪些业务事实。 查询不改变事实,草稿部分改变事实,发起流程开始改变事实,自动执行则直接进入业务结果层。这四类能力不应混在一起治理。
7.3 API 网关不只是通道,而是执行边界
很多企业把 API 网关理解成一个集成层。对 AI+ERP 来说,它的角色要更重一些。它不仅是通道,还是执行边界。
一个成熟的 API 网关,至少要承担这些能力:
身份认证
权限校验
限流与防滥用
幂等控制
审计日志
沙箱环境
版本管理
回滚与补偿机制
如果没有这些能力,Agent 看起来能调接口,实际无法进入生产环境。因为它既不安全,也不可控。
7.4 业务 API 必须封装完整逻辑,而不是只开放 CRUD
ERP API 不应只是简单的增删改查接口。对 Agent 来说,真正可用的是封装好业务逻辑的 API。比如“生成采购申请草稿”“发起异常审批”“根据库存规则生成调拨建议”“创建财务复核任务”,这些都比单纯的“写一条单据记录”更适合开放给 Agent。
原因很简单。Agent 并不擅长替代业务规则。API 层应该提前把业务规则固化进去,让 Agent 在规则边界内调用能力,而不是让 Agent 自己去重新发明业务逻辑。
可以用一个简单流程图来表示 Agent 执行链路。
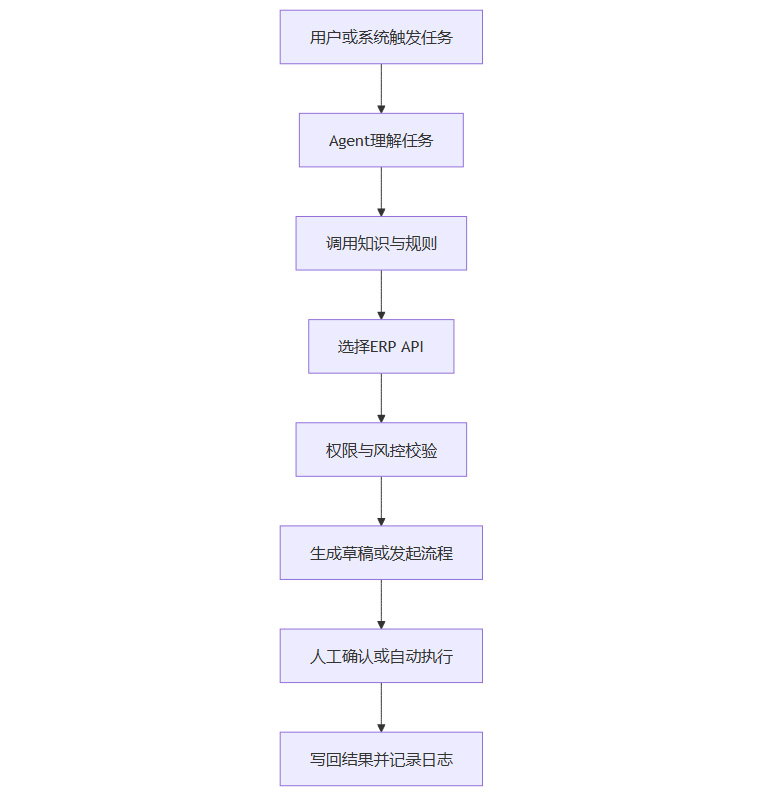
这个流程的核心不是“智能”,而是把每一步都放进可控链条。
🛡️ 八、安全治理层,权限、安全、日志与审计必须前置设计
8.1 AI 进入 ERP 后,安全问题不再只是传统权限问题
ERP 本来就有权限体系,但 AI 进入后,安全问题会明显升级。因为 Agent 不是普通用户。它可能横跨多个模块,调用多个工具,读取多种数据,再把结果写回流程。传统权限系统如果不调整,往往不是太松,就是太粗。
除了传统的越权问题,AI 场景还会出现新的风险面。比如提示注入,推理链被污染,外部模型调用时敏感数据暴露,Agent 调用工具时携带过多上下文。这些都不是传统 ERP 项目中最常见的风险,却会在 AI 时代变成新的薄弱点。
8.2 最小授权原则必须从用户扩展到 Agent
AI 权限设计的第一原则,仍然是最小授权。只是这里的“最小授权”不只针对人,也针对 Agent。Agent 不应因为是系统组件,就默认拥有比用户更大的数据权限和操作权限。
成熟设计通常会把权限拆成几层:
数据读取权限
知识检索权限
工具调用权限
草稿生成权限
流程发起权限
自动执行权限
不同 Agent 只获得完成当前任务所需的最小集合,而不是一把抓地给全量权限。AI 权限如果没有被显式建模,迟早会演化成系统级安全漏洞。
8.3 日志必须升级为“Agent 行为日志”
传统 ERP 日志主要记录用户操作。AI+ERP 场景中,日志必须升级为 Agent 行为日志。它至少要回答几个问题。是谁触发了 Agent。Agent 做了哪些步骤。调用了什么工具。用了哪些输入。生成了什么输出。结果有没有执行。执行是否成功。中间有没有被人工中断。
建议采用结构化日志字段,例如:
agent_id
session_id
user_id
step_sequence
action_type
tool_name
input_hash
output_hash
result_code
timestamp
这类日志的价值很大。它不仅用于故障排查,更用于事后追责、风控审计和问题回溯。如果未来企业要把 Agent 真正放进核心流程,没有这类日志,几乎不可能通过审计和风控。
8.4 审计和回滚,是 AI 进入生产环境的门槛
ERP 场景不怕 AI 给建议,最怕 AI 给错误建议后又无法拦截,或者 AI 执行错误动作后又无法恢复。所以,安全治理层不能只停留在权限与日志,还必须包含审批链路、风险拦截和回滚机制。
任何涉及写入 ERP 的动作,都应至少具备三件事:
能否审批
能否追踪
能否撤销或补偿
可以用下面这张表总结治理要求。
没有治理层,AI 进入 ERP 不是升级,而是风险转移。
🏛️ 九、AI 中台 / 智能中枢,平台化能力沉淀的关键
%20拷贝.jpg)
9.1 为什么企业最后都需要一个 AI 中台
很多企业初期做 AI+ERP,通常从局部场景开始。财务做一个问答助手,采购做一个评分模型,仓储做一个异常预警,法务做一个合同抽取。初看都有效,但随着场景增多,很快会遇到重复建设、权限不统一、提示词口径不一致、知识库多头维护、日志彼此分裂的问题。
这时候就会暴露出一个结构性问题。企业没有一个统一的能力沉淀层。也就是说,AI 被当成功能在各处安装,却没有被当成基础能力统一治理。
AI 中台的意义,就在这里。它不是为了再造一个大平台,而是为了把已经分散出现的模型、知识、Agent、查询、日志、权限、评估能力收回来,形成统一能力底座。
9.2 AI 中台应该承担哪些职责
一个成熟的 AI 中台,通常至少应承担这些职责:
统一数据服务
统一模型接入与版本管理
统一 Agent 编排
统一知识库管理
统一向量检索
统一 API 网关
统一权限控制
统一提示词与规则模板管理
统一日志监控与审计
统一效果评估与反馈闭环
它更像企业智能化的“操作中枢”,而不是某个部门的单点工具箱。
9.3 AI 中台的真正价值,在于避免智能能力再次烟囱化
ERP 之所以重要,本来就是因为它解决了业务系统烟囱化的问题。如果企业做 AI+ERP,最后又让每个部门各建一套智能能力,就等于在 ERP 之上又重新造了一层烟囱。
所以,AI 中台的价值不只是技术复用,更是治理复用。它让企业可以在统一的数据语义、统一的知识来源、统一的权限和统一的日志体系下,持续扩展新的智能场景。
可以把 AI 中台在架构中的位置理解为横向支撑层。
🛠️ 十、落地建议,从技术栈走向工程化
10.1 先做数据与知识分层,再谈智能问答
企业最容易犯的错误,是把结构化 ERP 数据和非结构化企业文档一股脑交给模型。更合理的做法,是把数据与知识分层治理。ERP 数据进入数据服务和语义层,制度文档进入知识库层,再通过 RAG 和查询编排做统一问答。
10.2 先做查询和建议,再做执行
执行层永远应是最后一步。企业可以先让 AI 查询、解释、总结、推荐,再逐步进入草稿生成、流程发起,最后才考虑低风险自动执行。这个顺序不是保守,而是生产系统的基本节奏。
10.3 统一 API 与权限,不要让 Agent 直接碰库
数据库不是 Agent 的工作界面,API 才是。任何需要改变业务事实的动作,都应通过封装业务逻辑的 API 完成,同时继承权限、记录日志、接受风控和审计约束。
10.4 日志与审计不是附属模块,而是生产能力
很多企业把日志放到项目后期补。这在 AI+ERP 里行不通。没有结构化日志,就没有稳定的排障能力、可追责能力和风控能力。没有日志与审计,AI 不应进入 ERP 核心流程。
10.5 尽早建设 AI 中台,而不是后期拆烟囱
早期统一模型、知识库、权限、日志和 Agent 编排,看起来工作量更大,实际比后期拆分散能力的成本低得多。企业越早平台化,后面的创新成本越低,治理难度也越低。
结论
企业如果要让 AI 真正进入 ERP,技术架构就必须从“功能叠加”转向“体系化设计”。ERP 本身已经提供了主数据、交易数据和流程数据这些事实基础,但这只是起点。企业还需要用数据治理与语义层让 AI 看懂这些数据,用多模型协同而不是单一大模型去解决不同类型的问题,用企业知识库补足制度与流程上下文,用 RAG 与结构化查询双轨机制来回答不同类型的问题,用标准 API 和 Agent 执行层把智能能力真正送进流程,再用权限、安全、日志、审计和回滚机制把整套体系治理起来。
从架构视角看,真正成熟的 AI+ERP 不是“ERP + 一个模型”,而是 ERP 数据底座 + 多模型能力 + 企业知识库 + 受控 API + 治理中枢 的组合。这套架构能否稳定运行,最终取决于四件事。
数据可理解
知识可检索
动作可调用
过程可治理
这四件事如果同时成立,AI 才不只是 ERP 外面的一个聪明入口,而会成为 ERP 内部真正可用、可控、可持续的智能中枢。企业智能化升级的深度,最后也不会由某个模型名称决定,而会由这套架构底盘的稳固程度决定。
📢💻 【省心锐评】
ERP 接上模型不难,难的是让模型读得懂、做得对、出了事还能追得回。
评论