.png)


美国的AI团队一直认为自己是全球领先者,但DeepSeek的出现让他们大吃一惊。DeepSeek在翻译流畅度上超越了ChatGPT和Gemini,甚至让马拉雅拉姆语用户都感到震惊。接下来,让我们一起来看看DeepSeek的基本原理,确保人人都能看懂。
现在的小孩子几乎都有自己的手机,甚至可以用父母的手机玩DeepSeek。DeepSeek几乎无所不知,父母用它给小朋友讲故事,解决简单的智力题目也不在话下。这些场景中,DeepSeek的核心功能就是问答。
DeepSeek的第一个模块R1
DeepSeek的第一个模块R1非常直接且强大,在数学、代码及自然语言推理领域与OpenAI o1比肩。你只要输入文字,它就会输出答案。比如你输入“starrBerrry”,它会给出4个字母的“答案”。

虽然这看起来像是开玩笑,但经过分析、推理和纠正,它真的给出了正确答案。
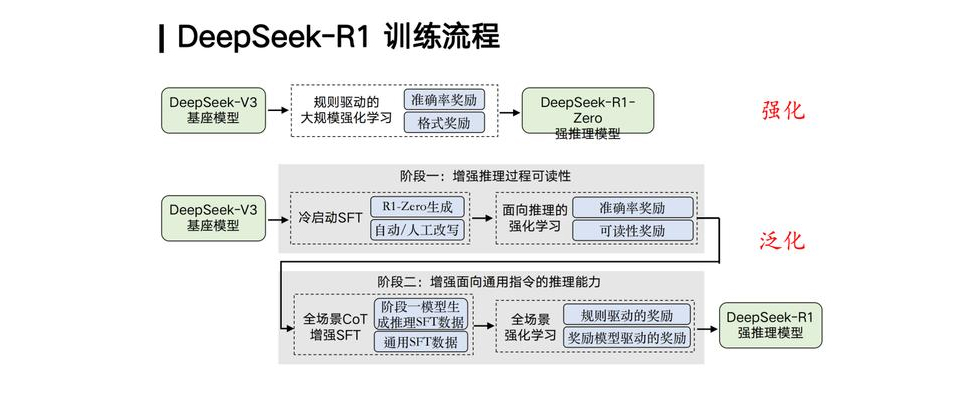
这是因为R1基于DeepSeek V3基座模型,通过特殊手段增强了LLM技术,得到了一个强推理模型,并采用了基于规则的方法。此外,R1还进行了深度推理SFT数据与通用SFT数据的混合微调,使得跨任务泛化更加精确和高效。
例如,我们在背诵乘法口诀时都知道一一得一,一二得二。但如果编一个不在乘法口诀中的内容,比如11x11=121,人类会知道这是错误的。但DeepSeek的回答依赖于公开数据,如果网上所有资料都包含11x11=121,那么它的回答会又快又准。
规则驱动强化学习
R1的规则驱动强化学习听起来高大上,但规则都是人定的,遇到新情况可能会抓瞎。因此,数据为王,实战中不断优化才是正道。这也是为什么大家一直强调学习AI的重要性。现在的AI虽然已经很智能,但仍处于初始阶段。接下来的3年内,AI将重塑和训练业务形态,特别是像百度、阿里巴巴、腾讯和字节跳动这样的企业巨头都在用AI重塑业务。这需要懂LLM的人来实现,也会衍生出很多AI岗位需求,据说大模型应用开发可以高达60K的offer。
DeepSeek-V3的技术细节
DeepSeek-V3是一款强大的混合专家(MoE)语言模型,总参数量达到6710亿,每个token激活370亿参数。其核心机制包括多头自注意力机制和前馈神经网络。
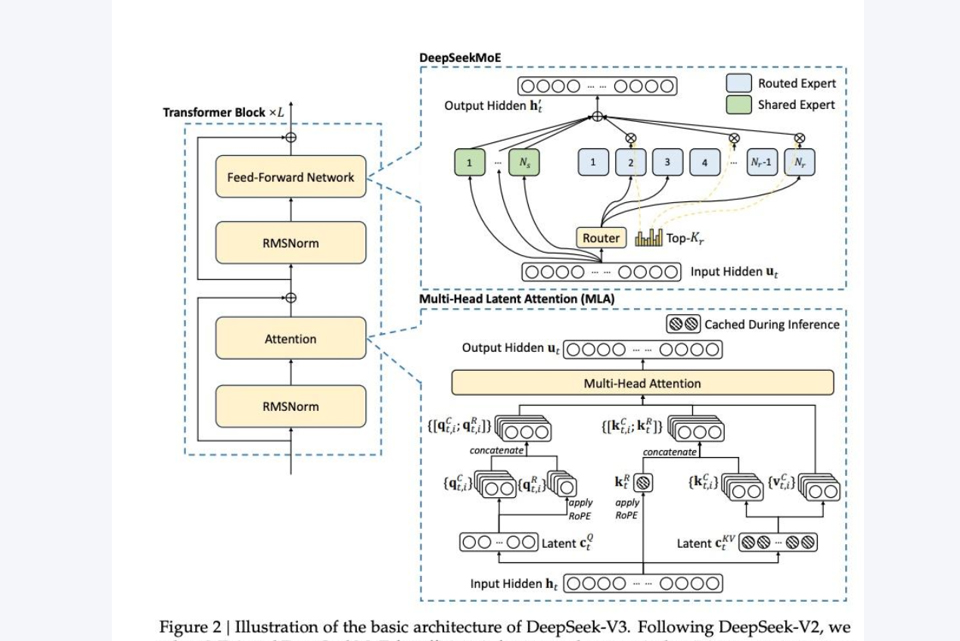
多头自注意力机制:能够同时关注多个部分的信息。

多头自注意力机制其实是这样
前馈神经网络:处理信息并生成输出。

前馈神经网络是这样的
DeepSeek-v3的内部实现非常巧妙,训练没有采用TP并行,而是针对MoE的AlltoAll做了极致优化。训练过程采用了FP8的混合精度训练,并设计了基于DualPipe的算法,利用pipeline并行机制,减少了pipeline bubble,提高了处理流信息的效率。
模型蒸馏
有人猜测DeepSeek蒸馏了GPT-4O模型的数据。其实,蒸馏在算法开发中是很正常的事。一般蒸馏是用大模型蒸馏小模型,减少部署开销,而DeepSeek是用GPT的小模型蒸馏大模型,以更少的成本获取较好的数据。DeepSeek也开放了自己的模型供他人使用,包括生成高质量数据。
DeepSeek在自家V3基础上,设计了一定的激励框架,弄出了一个r1-zero,然后用r1-zero训练出来的数据再回去训练V3,得到了R1。反复几次后,用R1产出高质量数据给阿里模型训练,效果非常好。
💡【省心锐评】
用工程思维突破理论瓶颈,这波中文互联网智慧暴击了算力崇拜,但数据投喂的天花板仍在逼近。

评论