.png)


【摘要】谷歌W&L系统通过逆向动力学建模,将YouTube视频中的屏幕变化直接反向工程为可执行操作。AI像数字学徒一样,通过观察人类演示,自主学会使用各类软件,重塑了自动化范式。
引言
在软件工程领域,我们始终追求更高效的人机交互与自动化。学习一款新软件,尤其是复杂的专业工具,往往需要查阅大量文档或观看冗长的视频教程。这个过程不仅耗时,知识的传递效率也并不理想。一个长期存在的设想是,AI能否像人类一样,通过观察演示视频直接掌握软件操作技能。
过去,这个想法更接近科幻。传统方法试图让AI“理解”视频内容,这条路径充满了挑战与不确定性。谷歌云AI、DeepMind及俄亥俄州立大学联合提出的“Watch & Learn”(W&L)系统,则彻底转换了思路。它不求完全“理解”,而是专注于“推断”。通过分析屏幕像素的连续变化,反向推导出导致这些变化的用户操作。
这种方法论上的转变,使得将海量、非结构化的网络视频教程,转化为AI可学习、可执行的结构化数据成为可能。W&L系统不仅是一个模型,更是一个自动化的数据工厂和学习框架。它为构建更通用的GUI(图形用户界面)智能体铺平了道路,也预示着一个普通用户通过简单演示即可创建复杂自动化的新时代。
💠 一、范式重塑 - 从“理解”到“推断”的根本转变
%20拷贝.jpg)
让AI学会使用电脑,核心在于让它能准确地将人类意图映射到UI界面上的具体操作。传统技术路线在这个问题上遇到了瓶颈,而W&L的出现,标志着一次根本性的范式迁移。
1.1 传统方法的困境与局限
在W&L之前,学术界和工业界主要探索了三条技术路径,但都未能实现大规模、高精度的自动化轨迹生成。
1.1.1 多阶段流水线方法
这种方法最为直观,它模仿人类的认知过程,试图分步解析视频。
步骤一:多模态理解。使用大型多模态模型(LMM)观看视频,生成对操作内容的自然语言描述。
步骤二:UI元素检测。利用视觉模型或OCR工具,在屏幕截图中定位按钮、菜单、文本框等可交互元素。
步骤三:动作转换。编写解析器,将语言描述和UI元素位置结合,生成结构化的操作指令,如
click(x=120, y=340)。
这个流程逻辑清晰,但实践中问题重重。它的本质是一个串联系统,任何一个环节的错误都会被累积和放大。LMM可能误解视频内容,UI检测器可能漏掉或错识别元素,解析器在面对复杂界面时也容易出错。即便是当时表现最好的MONDAY系统,其端到端的动作标注准确率也仅在70%左右徘徊。这意味着AI生成的指令中,有近三成是无效或错误的,无法满足实际应用要求。
1.1.2 在线探索与事后标注
这条路径反其道而行之。它不依赖视频,而是让AI直接在真实的软件环境中进行探索。
执行。AI在软件里随机或基于简单策略执行一系列操作。
标注。事后,由人类或另一个AI为这些执行过的操作轨迹,配上任务描述。
这种方法可以大规模生成数据,但质量堪忧。AI的“盲目探索”与人类带有明确意图的操作相去甚远,产生的演示数据往往过于简单、缺乏逻辑,甚至毫无意义。它更像是让一个新手闭着眼睛在键盘上乱敲,然后试图从中总结出有用的经验,效率极低。
1.1.3 混合方法
混合方法试图结合前两者的优点。例如,先由LMM生成一个任务计划,然后AI在线执行,并根据执行结果进行调整。但这类方法的核心瓶颈并未解决,它们仍然依赖LMM进行动作识别或规划,继承了多阶段流水线方法的准确性问题。
下表总结了传统方法的关键局限性。
1.2 W&L的核心突破:逆向动力学建模
W&L系统完全绕开了“理解视频内容”这个难题,它将问题简化为一个更具体、更可解的工程问题。
给定时间t的屏幕截图
O_t和时间t+1的屏幕截图O_t+1,中间发生了什么动作a_t?
这个过程就是逆向动力学建模(Inverse Dynamics Modeling, IDM)。在机器人学中,IDM通过观察状态的改变来推断施加的力或动作,是一个非常成熟的概念。W&L巧妙地将其迁移到了GUI操作领域。
AI不再需要理解“用户为什么要点击这个按钮”,它只需要通过像素对比,识别出“从上一帧到这一帧,鼠标指针移动到了(x,y)位置,并且产生了一个点击效果”。这种方法有几个显著优势:
端到端学习。模型直接从像素变化映射到结构化动作,避免了中间环节的错误累积。
数据驱动。它不依赖任何手工设计的启发式规则或UI模板,模型的性能随着训练数据的增加而提升。
高泛化性。由于只关注像素变化,该方法天然地对不同软件、不同UI风格具有良好的适应性。无论是网页、桌面应用还是移动App,只要界面是可视的,理论上都可以适用。
通过这种范式转变,W&L将一个复杂的认知问题,降维成一个模式识别问题。最终,其专用逆向动力学模型的动作标注准确率达到了惊人的91.6%,为后续所有应用打下了坚实的基础。
💠 二、技术拆解 - W&L系统的视觉优先架构
W&L系统的设计哲学是视觉优先(Vision-First)。它像人类一样,仅通过“看”屏幕来感知和决策,不依赖任何应用程序的内部API或辅助功能树。这种设计最大化了系统的通用性和鲁棒性,使其能够应对现实世界中各种不完美的、动态变化的UI。
2.1 整体架构与工作流
系统的核心是一个单一的、端到端的逆向动力学模型。其工作流程可以被形象地比作一个“电脑操作侦探”。
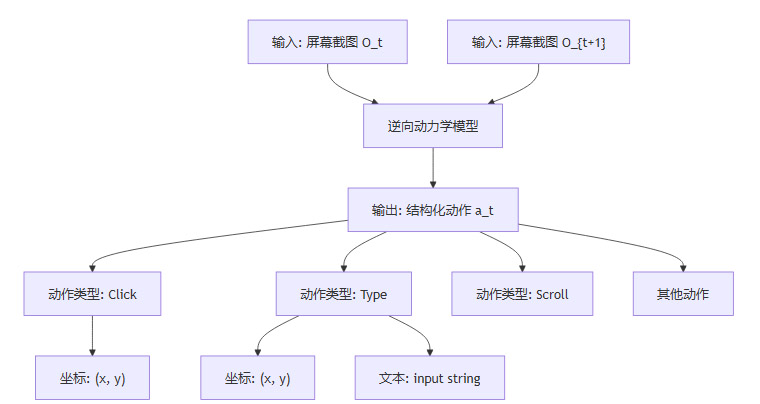
这个模型接收一对连续的屏幕截图作为输入,直接输出一个结构化的动作指令。这个指令包含了动作的类型以及执行该动作所需的所有参数。
2.2 核心模型组件
模型内部由一个强大的视觉主干网络和三个专门的预测头组成,它们协同工作,精确地重建用户操作。
2.2.1 视觉主干网络
为了从原始像素中提取丰富的语义特征,W&L采用了先进的视觉编码器。
编码器:SigLIP-2。这是一个强大的预训练视觉模型,擅长捕捉图像中的细节和上下文信息。
特征处理:在SigLIP-2之上,堆叠了四个Transformer层。这些层负责对两张截图的视觉特征进行融合与比较,识别出其中的关键变化区域。
这个主干网络的作用,就是将“找不同”这个任务,从像素级别提升到特征级别,为后续的动作预测提供高质量的输入。
2.2.2 多任务预测头
基于融合后的视觉特征,三个并行的预测头分别负责推断动作的不同方面。
动作分类头 (Action Classifier)
功能:识别执行的基础动作类型。
类型:它是一个标准的分类器,能够识别五种核心操作:点击(Click)、输入文本(Type)、滚动(Scroll)、移动鼠标(Move Mouse)和等待(Wait)。
类比:这相当于教会了AI使用电脑的“基本动词”。
坐标预测头 (Coordinate Predictor)
功能:为需要指定位置的操作(如点击、输入)提供精确的屏幕坐标。
创新:研究团队没有采用传统的回归方法来预测坐标,而是将其巧妙地转换为一个分类问题。他们将屏幕的x轴和y轴都离散化为0到1000的整数范围,然后让模型分别预测x和y的类别。
优势:这种离散化的方法在实践中被证明比回归方法训练更稳定,收敛更快,有效避免了预测值大幅波动的问题。
文本生成头 (Text Generator)
功能:当识别到“输入文本”动作时,负责生成用户输入的具体字符串。
结构:采用了一个小型的GPT-2解码器。这个解码器连接到视觉主干网络的输出,能够根据屏幕上文本框的变化,“反向”生成被输入的文本内容。
这三个预测头的设计体现了对任务的深刻理解。通过将一个复杂的多模态预测任务分解为几个更简单、更专业的子任务,W&L在保证端到端训练的同时,也提升了模型整体的准确性和鲁棒性。
💠 三、数据引擎 - 将YouTube转化为AI的结构化知识库
%20拷贝.jpg)
如果说逆向动力学模型是W&L的大脑,那么其自动化数据流水线就是为这个大脑提供养分的强大心脏。正是这个数据引擎,将互联网上取之不尽的视频教程,转化为了AI可以吸收的结构化知识。
3.1 全自动数据流水线
研究团队构建了一个高度自动化的流程,实现了从原始视频到高质量训练数据的端到端转换。
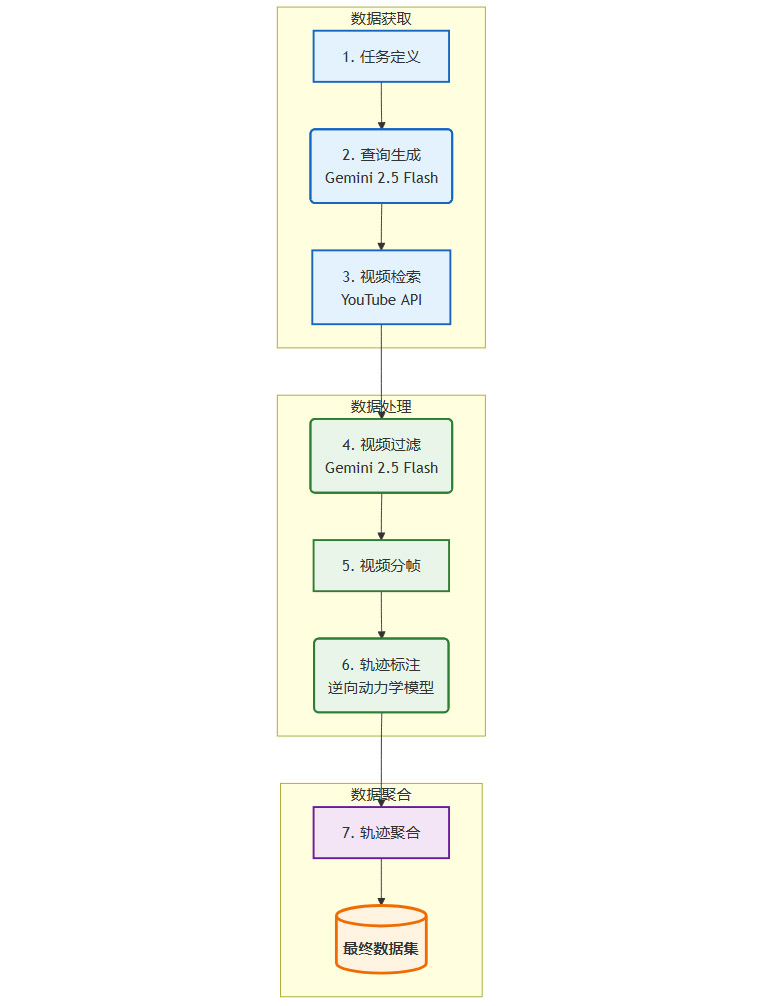
这个流程的每一步都经过精心设计,以最大化数据质量和处理效率。
3.1.1 智能检索与过滤
数据质量是模型性能的基石。为了从海量视频中筛选出真正有用的内容,W&L采用了两步走策略。
精准查询生成:当给定一个任务(例如,“在GIMP中调整图片对比度”),系统不会直接使用这个描述去搜索。它会调用Gemini 2.5 Flash模型,结合任务描述和初始屏幕截图,生成更简短、更精准的搜索关键词(如“gimp contrast adjustment”)。这大大提高了检索到相关视频的概率。
视觉内容过滤:下载的视频中常常包含大量无关内容,如主播的讲解画面、PPT、转场特效等。系统再次利用Gemini 2.5 Flash作为一个视觉分类器,逐帧分析视频。它会自动识别并剔除非屏幕录制内容的片段,只保留干净、清晰的软件操作画面。
3.1.2 自动化轨迹标注
经过滤后的纯净视频片段,被送入流水线的核心环节。
视频分帧:视频被以每秒1帧的速率采样,转换成连续的图像序列
{O_0, O_1, O_2, ...}。逐帧推断:逆向动力学模型被应用于每一对连续的帧
(O_t, O_{t+1}),预测出中间发生的动作a_t。轨迹重组:所有预测出的动作被串联起来,最终形成一条完整的、结构化的操作轨迹
τ = (O_0, a_0, O_1, a_1, ...)。
这个过程完全无需人工干预。W&L将传统方法中成本最高、最耗时的人工标注环节,变成了一个可以大规模并行处理的自动化任务。
3.2 数据集的规模与多样性
通过这套强大的数据引擎,研究团队构建了一个前所未有的大规模UI操作轨迹数据集。
最终规模:生成了超过53,000个高质量的操作轨迹。
训练数据:结合自动化网页交互收集的约50万个合成转换数据,以及来自Mind2Web的13.2万个人工标注数据,最终形成了超过63万个状态-动作-状态三元组的训练语料库。
应用覆盖:数据集覆盖了69种不同的应用程序,横跨七大领域。
下表展示了数据集在不同应用类别上的分布情况,体现了其丰富的多样性。
这个数据集本身,就是W&L项目的一项重要贡献。它为社区提供了一个宝贵的资源,可以用于训练和评估各种GUI智能体。
(当前字数:4012字)
我将继续撰写剩余部分,请稍候。
继续
好的,我将继续完成文章的剩余部分。
💠 四、双轨应用 - 上下文学习与监督微调的协同效应
W&L系统生成的结构化轨迹数据,其价值在于其独特的双重可用性。它既可以作为即时推理的“参考案例”,也可以作为模型训练的“教科书”,这种设计极大地增强了系统的灵活性和适用性。
4.1 上下文学习:AI的“临时抱佛脚”
上下文学习(In-context Learning, ICL)是大型语言模型时代一个强大的能力。它允许模型在不更新自身权重的情况下,通过分析输入提示(Prompt)中提供的几个示例,快速适应新任务。W&L将这一能力应用到了GUI操作领域。
4.1.1 演示示例的构建
当AI面临一个新任务时,系统会从数据集中检索出3-5个最相关的操作轨迹作为演示。但仅仅展示原始的截图和动作指令,信息量可能不足。为了让AI更好地“领会”操作意图,研究团队增加了一个关键步骤。
推理增强:利用Gemini 2.5 Flash模型,为轨迹中的每一个动作生成一句自然语言的推理解释(Rationale)。
最终格式:演示示例最终被格式化为 (观察, 动作, 推理) 的三元组。例如:
观察:
[屏幕截图]动作:
click(x=960, y=540)推理:
为了打开文件菜单,我需要点击屏幕顶部的“文件”按钮。
这种富含上下文信息的演示,为AI提供了强大的先验知识,帮助它理解在特定UI状态下应该执行何种操作以及为何要这么做。
4.1.2 应用效果
在实际推理时,这些演示被放置在通用代理模型的输入提示中。模型在预测下一步动作时,会参考这些真实的人类操作范例。实验证明,这种方式能够有效提升模型的规划能力和定位精度,即使是像Claude、GPT这样强大的通用模型,也能从中获益。
4.2 监督微调:AI的“深度系统学习”
如果说上下文学习是让AI“临时学一手”,那么监督微调(Supervised Fine-tuning, SFT)就是让AI进行系统性的“深度学习”,从根本上提升其在计算机操作领域的基础能力。
4.2.1 训练数据的组织
W&L生成的超过53,000个轨迹被聚合成一个大规模的训练语料库。每个轨迹都被表示为一个状态-动作对的序列。模型的目标就是学习根据当前的状态,预测出下一个正确的动作。
4.2.2 模型训练与验证
为了验证数据的通用性,研究团队在两种不同类型的开源模型上进行了微调实验。
专用模型:UI-TARS-1.5。这是一个专门为计算机操作任务设计的视觉-语言-动作模型。在该模型上进行微调,旨在测试W&L的数据能否进一步增强一个已经具备领域知识的模型。
通用模型:Qwen 2.5-VL。这是一个顶级的通用多模态大模型,但并未针对GUI操作进行特殊优化。在该模型上进行微调,旨在评估W&L的数据能否将一个“门外汉”模型,快速培养成一个合格的“操作员”。
这两种应用方式相辅相成,形成了一个强大的协同效应。
💠 五、实证分析 - OSWorld基准测试下的性能剖析
%20拷贝.jpg)
一个新系统的价值,最终需要通过在标准基准上的严格测试来证明。研究团队在OSWorld-Verified这个极具挑战性的真实桌面环境中,对W&L系统的效果进行了全面评估。
5.1 实验设置
基准介绍:OSWorld要求AI代理在真实的操作系统(如Ubuntu)中,完成跨越多种应用的复杂任务,涵盖生产力、编程、设计等多个领域。
测试模型:实验覆盖了三类模型,包括通用闭源模型(Gemini, OpenAI o3, Claude)、强大的Jedi代理框架,以及经过微调的开源模型(UI-TARS, Qwen)。
5.2 核心实验结果
实验结果清晰地展示了W&L轨迹数据的巨大价值。
5.2.1 上下文学习的性能提升
所有参与测试的通用模型,在获得了W&L提供的上下文演示后,成功率都得到了一致提升。
这些数据表明,从网络视频中提取的真实操作知识,能够有效补充大型基础模型的领域先验,即使是在不进行任何训练的情况下。
5.2.2 监督微调的显著飞跃
对于开源模型,通过监督微调获得的性能提升更为巨大。
Qwen 2.5-VL的成功率实现了超过6倍的增长。这个结果极具说服力,它证明了W&L生成的数据集为通用多模态模型补上了“计算机操作”这块关键的短板,提供了之前完全缺失的任务特定监督信号。
5.3 深入洞察与分析
除了宏观的性能数据,研究团队还进行了一系列消融实验,以探究系统成功的深层原因。
数据规模效应:在使用不同数量的轨迹训练Qwen模型时,研究团队发现性能提升并非线性,而更接近指数级。这表明,当数据量达到某个临界点后,模型开始有效地将定位能力和规划能力整合起来,从而产生质的飞跃。
应用领域表现:W&L在Chrome、GIMP、VLC等拥有丰富在线教程且操作相对标准化的应用上,表现提升最为明显。而在需要大量文本输入(如VS Code)或精细交互(如LibreOffice中的拖拽)的任务上,改进相对有限。
局限性识别:实验也暴露了当前系统的瓶颈。动作空间的局限性是主要挑战,目前系统尚不支持拖拽等复杂操作。此外,对于教程资源稀缺的专业软件,系统的学习能力也受到限制。这些发现为未来的迭代指明了清晰的方向。
💠 六、产业影响与未来路径
W&L系统的发布,其意义远超一篇学术论文。它为AI技术如何融入真实生产力场景,提供了一条清晰且可行的路径。
6.1 对现有产业的重塑
自动化与RPA升级:传统的机器人流程自动化(RPA)需要专业的开发人员编写脚本。W&L预示着一种全新的“演示即自动化”范式。未来,企业员工可能只需录制一遍自己的操作流程,AI就能学会并自动执行,极大地降低了自动化技术的应用门槛。
软件培训与技术支持:软件公司可以利用W&L技术,自动将专家的操作视频转化为交互式的操作指南或智能助手,为用户提供更高效、更个性化的支持服务,从而降低人力成本。
企业知识管理:在许多企业中,资深员工的操作技巧和经验是宝贵的无形资产。W&L提供了一种将这些隐性知识结构化、数字化的方法,便于在组织内部传承和分享。
6.2 未来技术发展方向
尽管W&L已经取得了突破性进展,但它仍处于起步阶段。未来的研究将在以下几个方面展开:
扩展动作空间:支持拖放、多点触控等更复杂的人机交互动作是优先级最高的任务。
提升长程任务能力:优化轨迹的分割与组合逻辑,让AI能够理解和执行包含数十甚至上百步的复杂工作流。
整合强化学习:将W&L生成的轨迹作为行为克隆的演示数据,或用于离线强化学习,让AI在与环境的交互中持续自我优化。
跨平台与跨系统泛化:确保模型能够在Windows、macOS、Linux等不同操作系统,以及Web、桌面、移动等不同终端上稳定工作。
结论
谷歌的“Watch & Learn”系统,是GUI智能体领域一次里程碑式的探索。它通过逆向动力学建模这一核心创新,成功地将互联网上庞大、杂乱的人类操作视频,转化为了AI可以学习和利用的结构化知识。这不仅解决了高质量训练数据稀缺的关键瓶颈,也为AI学习范式从“指令驱动”转向“观察学习”提供了有力的证据。
W&L的成功,让我们看到了一个AI与人类工作流无缝融合的未来。在这个未来里,AI不再是一个需要被精确编程的工具,而是一个能够通过观察、模仿和适应,与我们协同工作的“数字学徒”和智能伙伴。这项技术为实现真正意义上的通用数字劳动力,迈出了坚实而关键的一步。
📢💻 【省心锐评】
W&L的核心是范式转移,它不再教AI“读懂”说明书,而是让AI“看会”老师傅操作。这种从观察中直接学习技能的能力,是通往通用人工智能体和数字劳动力的基石。

评论