.png)


【摘要】AI应用的竞争焦点正从单一模型能力转向系统级“智力流架构”。通过任务拆解与流程编排,新一代工具实现了更高的可靠性与效率,预示着行业发展的范式转移。
引言
近期,Perplexity与NotebookLM两款AI工具在技术圈内引发了广泛讨论。许多从业者的第一反应是探究其背后是否搭载了更强大的基础模型。然而,深入剖析其技术内核,我们会发现一个更为深刻的趋势。它们的成功并非源于模型参数的暴力堆砌,而是得益于一种更精巧、更务实的设计哲学——“智力流架构”(Intelligence Flow Architecture)。
这个概念的核心,是将AI的能力从一个大而化之的“万能大脑”,重塑为一条目标明确、分工清晰的“思维管道”。它不追求让单一模型解决所有问题,而是将复杂的知识处理任务分解,构建成一条高效的自动化流水线。这标志着AI应用开发正在从“模型为中心”的蛮荒时代,步入“系统为中心”的精耕时代。本文将深入拆解这一架构范式,分析其技术原理,并通过具体案例揭示其如何解决当前大模型应用的瓶颈,最终探讨其对行业未来及个人发展的深远影响。
一、💠 “大力出奇迹”的大模型范式及其天花板
%20拷贝-zozj.jpg)
自Transformer架构问世以来,AI领域的主旋律便是“规模定律”(Scaling Law)。业界普遍认为,更大的模型、更多的数据、更强的算力,就能自然涌现出更强的智能。这种“大力出奇迹”的范式催生了GPT系列、Claude等一系列令人惊叹的通用大模型(LLM)。
1.1 规模竞赛的时代
当前AI竞争的主流叙事,无疑是围绕基础模型的规模展开的。科技巨头们投入数百亿资金,进行着一场关于模型参数、训练数据和算力集群的军备竞赛。其核心逻辑在于,通过在海量数据上进行无监督或半监督学习,让模型内隐地“记住”人类世界的庞大知识,并掌握复杂的语言规律,从而成为一个具备通用问答、创作、推理能力的“通用大脑”。
这种模式的优势显而易见。它极大地降低了AI应用的开发门槛。开发者无需为每个特定任务从零开始训练模型,只需通过API调用这些强大的基础模型,再辅以精巧的提示工程(Prompt Engineering),就能快速构建出功能丰富的应用。这本质上是一种中心化的智能供给模式,即由少数几个“超级大脑”为整个生态提供底层的认知能力。
1.2 范式之下的固有瓶颈
尽管通用大模型取得了巨大成功,但随着其在严肃、高价值场景中的应用加深,单一“大模型”模式的固有瓶颈也日益凸显。这些瓶颈并非通过简单的参数扩张就能解决,它们根植于模型本身的技术原理之中。
1.2.1 可靠性危机:“幻觉”的阴影
大语言模型本质上是一个概率预测引擎,它生成下一个词的依据是训练数据中的统计规律,而非事实逻辑。这就导致了其广为人知的“幻觉”(Hallucination)问题,即模型会自信地编造出看似合理却完全错误的信息。
在日常闲聊或创意写作中,幻觉或许无伤大雅。但在医疗诊断、法律咨询、金融分析、科学研究等对事实准确性要求极高的专业领域,幻觉的存在是致命的。一个基于幻觉的医疗建议或投资分析,可能导致灾难性后果。更棘手的是,由于模型内部决策过程的“黑箱”特性,我们很难有效预测或控制幻觉的发生。信息来源的不透明性,使其难以在严肃的知识工作场景中被完全信任。
1.2.2 经济约束:智能的高昂成本
“大力出奇迹”的背后是惊人的资源消耗。训练一个千亿参数级别的模型,需要动用数万块顶级GPU,持续运行数月,其单次训练成本动辄高达数千万甚至上亿美元。这还不包括海量数据的清洗、标注以及持续的基础设施维护费用。
推理成本同样不容小觑。用户每一次与大模型的交互,背后都是庞大的计算资源在支持。对于高并发的应用而言,API调用费用会迅速累积成一笔巨额开销。高昂的训练和推理成本,不仅限制了技术的普惠应用,也使得模型的快速迭代和定制化变得异常困难,形成了少数玩家才能参与的“富人游戏”。
1.2.3 整合摩擦:“最后一公里”的困境
通用大模型被设计为“万事通”,但并非针对任何特定工作流程进行了优化。当用户需要将其嵌入实际工作流时,往往会遇到巨大的“整合摩擦”。用户需要花费大量精力设计复杂的提示词,引导模型理解任务背景、遵循特定格式、调用外部知识。这个过程不仅繁琐,且结果不稳定。
此外,用户还需要在模型输出后进行繁重的事实核查、来源验证和内容修正工作。这使得AI在许多场景下更像一个需要时刻监督的“实习生”,而非一个能独立作业的“专家”。作为一个未经优化的“通用大脑”,它在解决具体、结构化任务时的效率并不高,用户体验的“最后一公里”问题始终未能得到妥善解决。
二、💠 范式转移:从模型为中心到“智力流架构”
面对上述瓶颈,业界开始探索新的出路。与其继续在“模型更大”的单一维度上内卷,不如转换思路,从系统工程的角度重新设计AI应用的工作方式。“智力流架构”正是在这一背景下应运而生。
2.1 “智力流架构”的核心定义
“智力流架构”并非指代某一种具体的AI模型,而是一套更聪明、更具系统性的工作范式。其本质是任务拆解(Task Decomposition)和流程编排(Process Orchestration)。
它不再将AI视为一个无所不晓的黑箱,而是将其看作一个可以被调度的“能力组件”。面对一个复杂的用户请求,该架构会像一位经验丰富的项目经理,首先将其分解为一系列更小、更明确的子任务,然后为每个子任务匹配最合适的工具或模型,最终将各环节的输出结果整合,形成一个完整、可靠的最终答案。
这个过程可以用一个高效厨房的比喻来理解。传统大模型应用就像一个天赋异禀但流程混乱的厨师,所有工序一把抓,出品质量全凭临场发挥。而“智力流架构”则构建了一条精密的后厨流水线,从洗菜、切配、烹饪到摆盘,每个环节都有专人(或专用工具)负责,分工明确,动线合理,最终上菜又快又准。其核心优势在于,通过流程化设计,让AI在每个环节都做自己最擅长的事,实现了“1+1>2”的系统效应。
2.2 工作原理:一条精密的认知流水线
一个典型的“智力流架构”在处理用户请求时,通常会遵循以下步骤。我们以“总结最近关于AI芯片的新闻并分析其对行业格局的影响”这个复杂请求为例,来展示其内部工作流程。
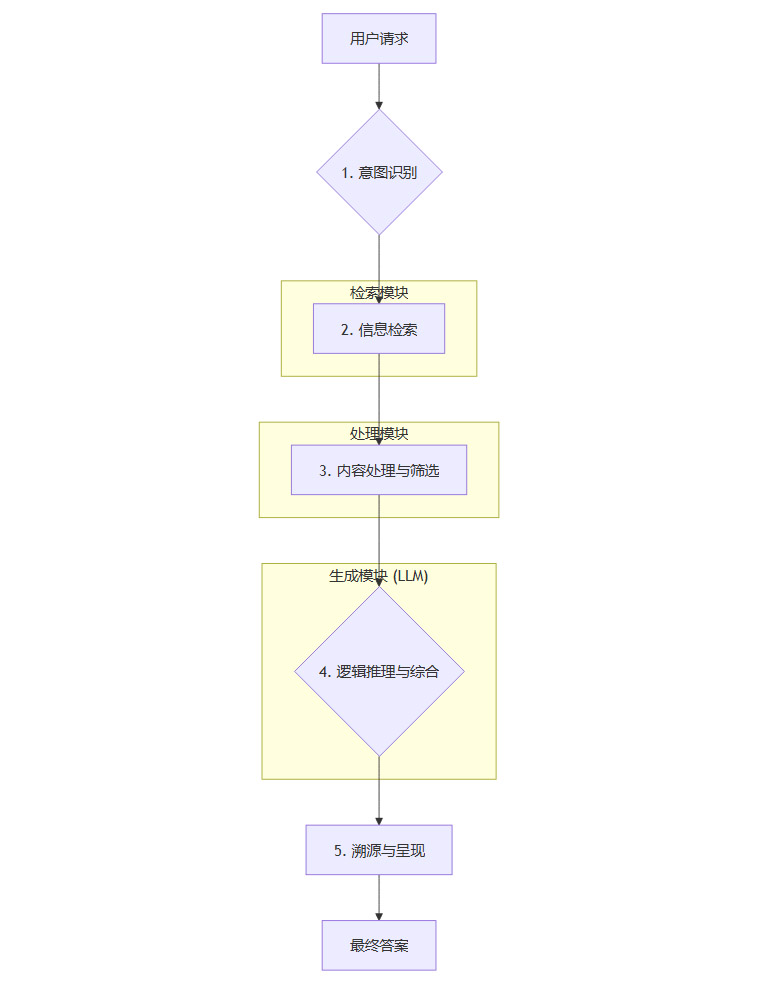
意图识别(Intent Recognition):系统首先需要精确理解用户的真实需求。上述请求包含两个核心意图,一是“信息汇总”(总结新闻),二是“分析评论”(分析影响)。一个轻量级的分类模型或规则引擎就能高效完成此任务。
信息检索(Information Retrieval):识别意图后,系统不会直接去问大模型。针对“总结新闻”的意图,它会调用搜索引擎API,使用“AI芯片 最新新闻”等关键词进行实时网络搜索。这确保了信息的时效性。
内容处理与筛选(Content Processing & Filtering):系统从搜索结果中获取到大量的网页链接和文本片段。接着,它会运行一个预处理程序,自动去除广告、导航栏等无关信息,提取正文内容,并根据相关性、权威性对信息源进行初步筛选和排序。
逻辑推理与综合(Logic Reasoning & Synthesis):这是大语言模型真正发挥作用的环节。系统会将上一步处理好的、干净的、高相关的文本片段,连同用户的原始问题,一起打包成一个结构化的提示(Prompt),发送给大模型。此时,大模型的任务不再是凭空回忆,而是基于给定的材料进行阅读理解、归纳总结和逻辑推理。它会先总结新闻要点,然后基于这些事实进行分析,得出对行业格局影响的结论。
溯源与呈现(Sourcing & Presentation):大模型生成答案后,系统会执行最后一步,也是至关重要的一步。它会将答案中的每一句关键论断,与原始的网页链接进行匹配和关联,生成清晰的引用和脚注。最终呈现给用户的,是一个包含直接答案、分析观点和可验证信源的完整报告。
2.3 关键技术支柱
“智力流架构”的实现,离不开几项关键技术的支撑。这些技术共同构成了这条认知流水线的基石。
2.3.1 检索增强生成(RAG)
RAG(Retrieval-Augmented Generation)是“智力流架构”的核心技术。它完美地解决了大模型知识陈旧和容易幻觉两大痛点。其基本思想是在模型生成答案之前,先从一个外部知识库中检索出相关信息,并将这些信息作为上下文(Context)一并提供给模型。
这个外部知识库可以是整个互联网(如Perplexity所做),也可以是一个私有的文档集合(如NotebookLM所做)。通过RAG,大模型的角色发生了根本性转变。
从“封闭记忆”到“开放参考”:模型不再仅仅依赖其在训练阶段“背诵”的内部知识,而是学会了“开卷考试”,可以参考实时、动态的外部信息源。
从“概率创作”到“有据生成”:模型的输出被检索到的事实所“锚定”(Grounding),大大降低了幻觉的概率,使其生成的内容更加可靠和可信。
2.3.2 Agent框架与工具调用
现代“智力流架构”往往以AI Agent(智能体)的形式存在。Agent的核心思想是赋予大语言模型一个“大脑”的角色,使其不仅能生成文本,还能**主动决策并调用外部工具(Tools)**来完成任务。
这些工具可以是多种多样的API,例如:
搜索引擎API(用于获取实时信息)
计算器API(用于精确数学运算)
数据库查询接口(用于访问结构化数据)
代码执行环境(用于编写和运行脚本)
通过Agent框架(如LangChain、LlamaIndex),开发者可以为大模型配备一个“工具箱”。当模型接到一个任务时,它会自行判断是否需要以及需要使用哪个工具,然后生成调用该工具所需的代码或参数,执行工具并获取返回结果,最后再利用这个结果继续下一步的思考或生成最终答案。这让AI从一个被动的语言模型,进化为一个主动的任务执行者。
2.3.3 多模型协同与成本优化
“智力流架构”并不迷信于单一的超大模型。相反,它提倡在合适的环节使用合适的模型。一个复杂的流程中,可能会包含多个不同规模、不同特性的模型协同工作。
例如,在上述流程中:
意图识别阶段,可以使用一个参数量较小、响应速度极快的模型(如DistilBERT),成本几乎可以忽略不计。
内容处理阶段,可以使用专门的摘要或嵌入模型(Embedding Model)来高效处理文本。
逻辑综合阶段,才需要动用能力最强、成本也最高的旗舰模型(如GPT-4或Claude 3 Opus),以保证最终输出的质量。
这种分层、异构的模型部署策略,可以在不牺牲最终效果的前提下,极大地优化系统的整体运行成本和响应延迟,使得构建高性能、低成本的AI应用成为可能。
下表清晰对比了两种范式的核心差异。
三、💠 架构实践:Perplexity与NotebookLM的实现拆解
%20拷贝-ibee.jpg)
理论的价值在于实践。Perplexity和NotebookLM正是“智力流架构”的两个典范级应用。它们分别针对“开放域信息探索”和“私有知识管理”这两个典型场景,给出了教科书般的解决方案。
3.1 Perplexity:开放世界的实时信息合成器
Perplexity的定位是“对话式答案引擎”,它旨在颠覆传统搜索引擎提供“链接列表”的模式,直接为用户提供精准、附带信源的答案。
3.1.1 架构流程拆解
Perplexity的“智力流”是一套典型的开放式探索流,其核心价值在于对外部公开信息的可信整合。
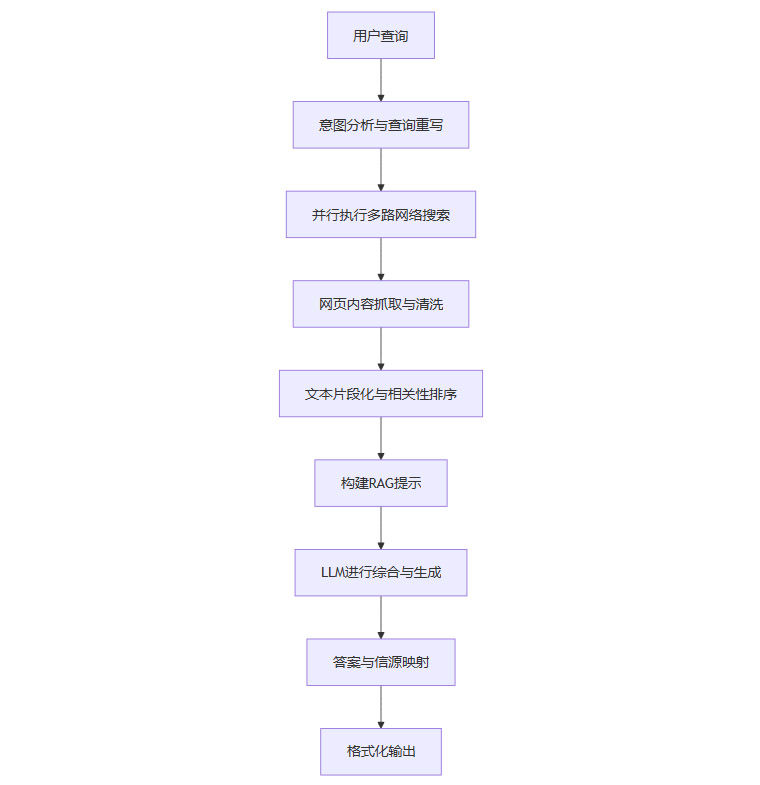
查询重写:当用户输入一个问题,Perplexity首先会对其进行分析,可能会将其改写成更适合搜索引擎的关键词组合。
并行搜索:系统会同时向多个信息源(包括自家的搜索引擎和第三方API)发出搜索请求,以求广度与速度。
信息聚合:它快速抓取排名靠前的网页内容,进行清洗,提取出高质量的文本片段(Snippets)。
RAG提示构建:系统将最相关的文本片段作为上下文,与用户的原始问题一起,构建一个信息丰富的提示。
LLM综合:此时,Perplexity调用一个强大的LLM(它会根据任务动态选择,可能是GPT系列、Claude系列或自研模型)。LLM的任务非常明确,即基于提供的上下文材料,忠实地回答用户的问题。
信源映射:在生成答案的每一步,系统都会追踪信息来源于哪个文本片段,以及该片段的原始网页链接。最终,它会将生成的答案与这些链接一一对应,以脚注的形式呈现给用户。
3.1.2 LLM角色的转变
在Perplexity的架构中,LLM的角色被巧妙地重新定义了。它不再是无所不知的“先知”,而是一个高效、精准的“信息综合处理器”。它的主要职责是阅读、理解、总结和组织信息,而不是凭空创造。这种设计,从根本上解决了传统搜索引擎“只给鱼竿不给鱼”和传统聊天机器人“给鱼但不告诉你鱼从哪来”的两难困境。
3.2 NotebookLM:封闭循环的个人知识引擎
与Perplexity面向广阔的互联网不同,Google的NotebookLM则专注于一个更私密、更聚焦的场景,即激活用户自己的知识资产。它像一位贴心的个人研究助理,帮助用户深度消化和利用自己上传的文档。
3.2.1 架构流程拆解
NotebookLM的“智力流”是一套封闭式知识流,其核心价值在于对私有知识的深度盘活。
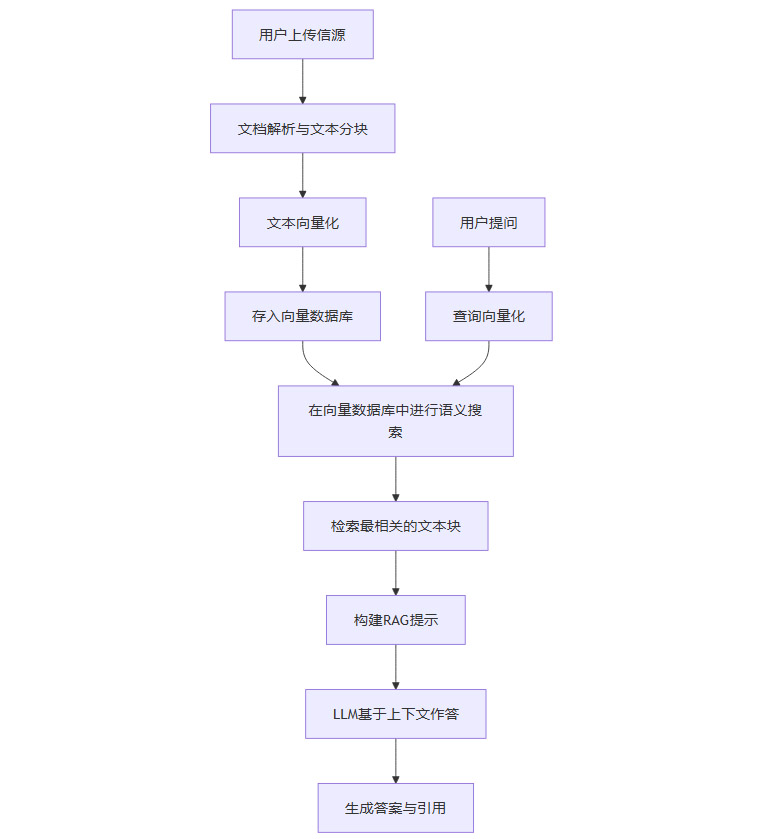
知识库构建:用户首先上传自己的资料。NotebookLM会对这些文档进行解析,将其分割成较小的文本块(Chunks),然后使用一个Embedding模型将每个文本块转换为一个高维向量,并存入专门的向量数据库中。这个过程相当于为用户的个人知识建立了一个可供语义检索的索引。
语义检索:当用户提出问题时,系统同样会将问题转换为一个向量,然后在向量数据库中进行相似度搜索,快速找到与问题最相关的几个原始文本块。
有据生成:系统将检索到的文本块作为唯一的上下文,提交给大模型(Google自家的Gemini Pro),并明确指示模型只能根据这些提供的材料来回答问题。
精准溯源:模型生成的答案会附带精确的引用,点击引用可以直接跳转到原始文档的具体位置,方便用户核对。
3.2.2 “知识沙盒”的价值
NotebookLM通过严格的RAG流程,为用户的知识交互构建了一个可信赖的“知识沙盒”。在这个沙盒里,LLM的发挥空间被严格限定在用户提供的资料范围内。这带来了几个核心优势:
杜绝外部幻觉:由于信息源完全封闭且可控,模型不会引入外部的错误信息或进行无根据的编造。
高度个性化:所有回答都与用户的个人知识体系紧密相关,实现了真正的个性化智能。
保护隐私:用户的文档数据在沙盒内处理,与通用的模型训练数据隔离,保障了信息安全。
无论是学生整理课程笔记,还是研究员分析论文,亦或是法务人员审阅合同,NotebookLM都将原本静态、杂乱的资料洪流,转化为了一个结构清晰、可供反复诘问和深度挖掘的交互式知识体系。
四、💠 未来展望:AI下半场的竞争逻辑与个人机遇
%20拷贝-jeod.jpg)
Perplexity和NotebookLM的成功,不仅仅是两个产品的胜利,它更像是一个信号,预示着AI应用开发的“下半场”已经拉开序幕。竞争的焦点,正在发生深刻的转移。
4.1 对行业:从基础模型到复合应用的价值跃迁
在AI发展的上半场,行业的目光聚焦于基础模型本身。谁的模型参数更多、能力更强,谁就拥有话语权。然而,随着各大厂商的基础模型能力逐渐趋同,单纯的模型优势正在迅速贬值。
下半场的竞争,关键将从“模型层”转向“应用层”和“架构层”。真正的护城河,不再是拥有一个最强的“大脑”,而是设计出最贴合用户真实工作场景的“思维管道”。未来的AI应用,将不再是调用单一模型API的薄层封装,而是由多个AI模型、非AI模块(如搜索引擎、数据库)、业务逻辑和用户界面深度耦合而成的“复合智能系统”(Compound AI Systems)。
这意味着,AI产品设计的核心,将从“如何让模型更强大”,转变为“如何通过聪明的架构,将现有AI能力最有效地传递给用户”。谁能更好地理解人类的工作逻辑,谁能将AI无缝嵌入真实的知识生产流程,谁就能在市场中赢得最终的用户。
4.2 对开发者与架构师:技能栈的重塑
这一趋势也对技术人员的技能栈提出了新的要求。过去,AI工程师的核心竞争力可能体现在模型训练、算法调优上。未来,系统集成和架构设计能力将变得同等重要,甚至更为关键。
新一代AI架构师需要具备的能力包括:
RAG系统设计与优化:精通向量数据库选型、Embedding模型调优、检索策略设计等。
Agent框架应用:熟练使用各类Agent框架,为AI设计合理的决策逻辑和工具调用能力。
成本与性能权衡:能够根据业务场景,设计出兼顾效果、成本和延迟的多模型协同方案。
领域知识建模:深刻理解业务,能够将复杂的业务流程,抽象和翻译成高效的“智力流”。
简而言之,未来的AI专家,将更像一个AI能力的“系统工程师”,而非仅仅是算法的“炼丹师”。
4.3 对普通用户:从AI使用者到AI工作流构建者
这场变革也为我们每个普通人带来了新的启示。与其被动地焦虑“AI会不会取代我”,不如主动思考“我该如何借助这些‘智力流’工具,来放大自己的专业能力”。
真正的效率革命,并非来自于使用某一个单一的、万能的AI工具,而是来自于将多个优秀的、专注的AI工具组合起来,打造属于自己的、个性化的“超级工作台”。
想象一下这样的工作流:
使用 Perplexity 进行前期课题研究,快速获取某个领域的最新动态和核心观点,并获得所有信源。
将收集到的高质量报告、论文和网页,全部上传至 NotebookLM,构建个人专属的课题知识库。
在 NotebookLM 中通过对话,对知识库进行深度挖掘、提炼要点、发现不同文献间的隐藏联系,并生成报告大纲。
最后,使用 Kimi 或 Claude 等长文本写作助手,将大纲和提炼的要点作为输入,快速生成报告初稿。
在这个流程中,AI不再是一个模糊的“助手”,而是被拆解为一系列功能明确的“组件”:信息搜集器、知识管理器、逻辑分析器、内容生成器。而人类的核心价值,在于设计、驱动和优化这个工作流。驾驭工具流的能力,将成为未来知识工作者的核心竞争力。
结论
从“万能大脑”到“思维管道”的演进,并非对通用大模型价值的否定,而是一次深刻的成熟与回归。它标志着AI技术正在褪去神秘的光环,从遥远的“通用人工智能”畅想,回归到解决当下具体问题的务实路径上来。
Perplexity和NotebookLM的探索证明,通过精巧的“智力流架构”,我们可以在现有模型能力的基础上,构建出远比单一模型更可靠、更高效、更具价值的应用。这场以系统工程思维驱动的变革,不仅为AI应用的开发者指明了新的方向,也为我们每一个希望在AI时代保持竞争力的人,提供了清晰的行动指南。AI终究是工具,而懂得如何驾驭和组合这些工具的人,才是这场变革中真正的主角。
📢💻 【省心锐评】
AI的价值不在于模型有多“大”,而在于工作流有多“顺”。未来的赢家,属于那些能将AI能力巧妙编排进真实业务流程的“管道设计师”,而非仅仅拥有最强“大脑”的巨头。

评论